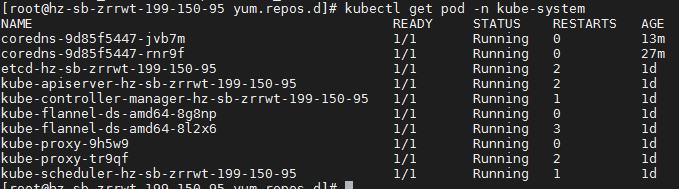
1、步骤一:K8S集群搭建完成后,发现2个coredns容器状态一直为CrashLoopBackOff,状态不断重启,在running和CrashLoopBackOff直接不停转换


2、步骤二:kubectl logs -f coredns-9d85f5447-ct5c8 -n kube-system命令查看pod日志如下
Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
kubectl describe pod coredns-9d85f5447-vhtc5 -n kube-system日志错误为
Readiness probe failed: Get http://172.17.67.3:8181/ready: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
从日志上看是到10.96.0.1的443网络不可达导致

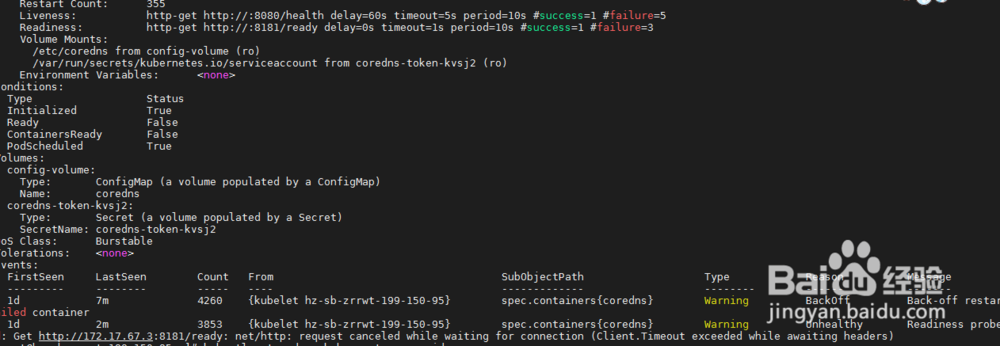
3、步骤三:此时发现两个pod节点都分配在master节点上,node节点没有分配上去,有了一个想法,删除一个coredns的pod,重新分配试试,执行 kubectl delete pod coredns-9d85f5447-ct5c8 -n kube-system命令删除其中一个节点,如图,集群马上重新创建了一个coredns节点,新的pod分配到了node 115上,等了一会,发现node节点上的pod状态竟然正常了,发现一个疑点,node节点上的pod ip为10.244.2.2,master节点的pod ip为172.17.67.3,记得当初k8s集群初始化使用的参数为--pod-network-cidr=10.244.0.0/16,原因应该为master节点地址分配有问题。
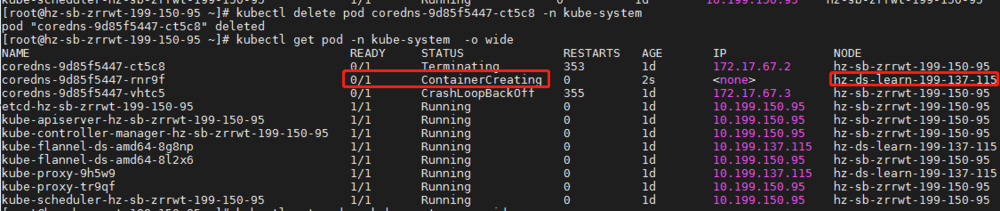

4、步骤四:通过步骤三的分析,我们分别在master节点上执行ip add查看flannel网卡地址分配情况。发现master节点cni0地址为172.17.67.1,而node节点地址为10.244.2.1,不在初始化分配地址段10.244.0.0/16内,我们找到原因了,将master节点pod地址重新分配即可。

5、步骤五:从资料上看,有网友建议kubeadm reset重置来解决,但是此方法比较麻烦,我采用如下方法
ip link set cni0 down;brctl delbr cni0
先停止cni0 网卡,然后使用brctl 命令删除此网卡,删除后flannel会立刻重新创建此网卡,使用ip add查看,网卡地址已经变成10.244段。
注意:
1:brctl 命令可以使用命令yum install -y bridge-utils安装
2:停止网卡可删除操作最好使用分号一起执行,否者停止后启动很快,会提示此网卡为up状态,不可删除。
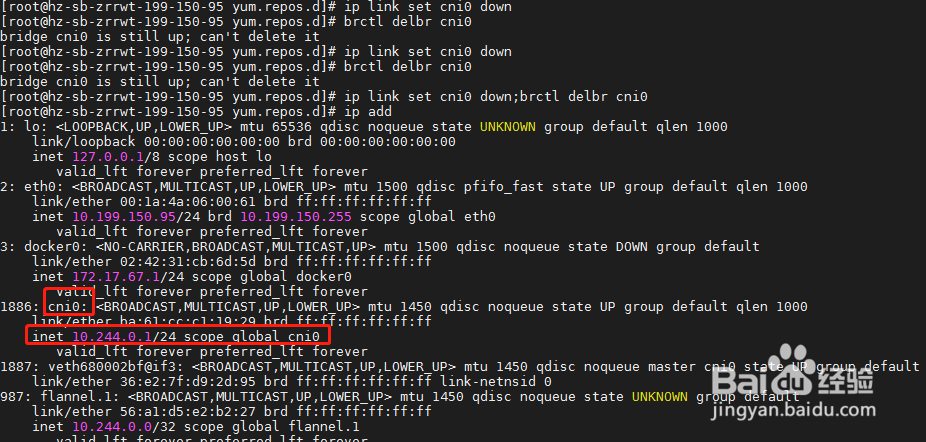
6、步骤六:最后再次使用 kubectl get pod -n kube-system命令检查,coredns的pod状态都显示正常,问题解决。