1、python3在使用urllib.request.urlopen或者urlllib.request.urlretrieve时候最好设置一个超时时间,这样在长时间获取不到内容时候可以做进一步的处理,打开python开发工具IDLE,新建‘timeout.py’文件,并写代码如下:
import socket
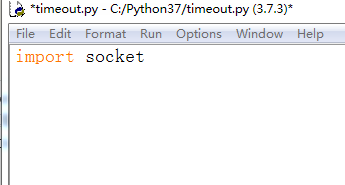
2、设置超时时间,以秒为单位,代码如下:
socket.setdefaulttimeout(30)
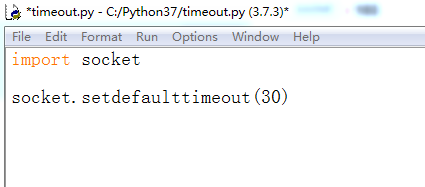
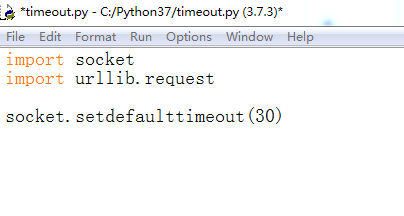
3、导入urllib.request包,代码如下:
import socket
import urllib.request
socket.setdefaulttimeout(30)
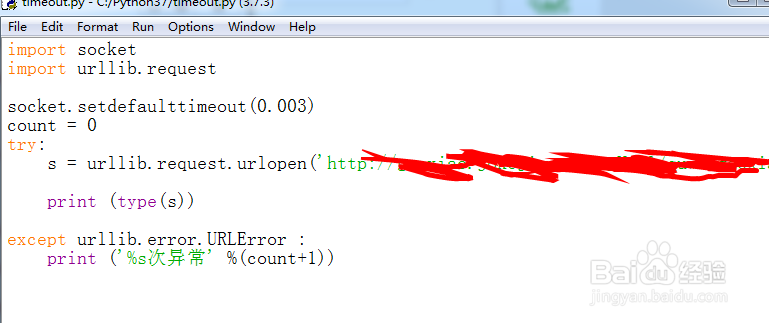
4、写一个测试脚本,把timeout时间改小,访问一个较耗时网址,具体网址就不透露了,会抛出异常,代码如下:
import socket
import urllib.request
socket.setdefaulttimeout(0.003)
s = urllib.request.urlopen('http://some')
print (type(s))

5、F5运行代码,就会出现timeout异常

6、接着处理抛出的异常,代码如下:
import socket
import urllib.request
socket.setdefaulttimeout(0.003)
count = 0
try:
s = urllib.request.urlopen('http://some')
print (type(s))
except urllib.error.URLError :
print ('%s次异常' %(count+1))
7、F5运行代码,捕捉到异常,可以进行处理,但是urlopen捕捉不到timeout异常,会被忽略,欢迎高手指点原因,urlretrieve可以捕捉到。一般可以设置个循环次数如果超过几次都会timeout异常,就可以选择记日志,不影响后续内容的抓取
