1、分类变量:若分组分析,选择相应的分组变量,在“最大类别”输入最大的分类数,默认25,超过规定分类数则不进行分析。
“个案标签”选择一定变量作为标记变量,也不可不选择。
“估计”方法选择如图所示的几个。


2、“模式”:“按照缺失值模式分组的表格个案”:以表格形式列出每个变量各种缺失方式的缺失例数。
“按照缺失值模式对变量排序”:缺失率太小的缺失方式不予显示,系统默认1%。
“变量”:规定用何变量标记观察单位观察单位及对结果排序。
“附加信息”:显示每个观察单位的观察值,对于列表方式如选择该项可给出定量变量侵仗的均数及分类变量每一类各种缺失方式的缺失数。
“排序依据”:没激活时是不能用的,选择一个变量,依据该变量大小依次列出各观察单位的结果。

3、“单变量统计分析”:给出每个变量的未缺失数、缺失数与缺失率,对于“定量变量”给出均数、标准差及极端值个数等。
“百分比不匹配”:以矩阵形式给出每一对变量不匹配(其中一个变量缺失而另一个变量不缺失)例数占总例数的百分比,对角线位置上即为单个变量的缺失率。
“T检验”:按照缺失指宙川示变量将各计量变量分为两组,用T检验比较两组均数有无差别,助于判断变量是否为完全随机缺失。
“交叉表”:按各分类变量分类给出其罩宿阅他变量的缺失数和缺失率及每种缺失方式的比例。
缺失率太小的不予显示,默认为5%。

4、“估计”:估计含有缺失值的变量的均数、相关阵和协方差矩阵。
按列表:各入选变量均无缺失值的观察单位参加估计。
成对:所有入选变量两两匹配,每对变量无缺失值的观察单位参加估计。
EM(Expectation-Maximization):期望-最大似然估计法,采用迭代法建模.关于EM建模法,先利用未缺失值建模估计缺失值的期望值,然后迭代计算,用最大似然估计法重新估计参数。
回归:多元线性回归估计缺失值,给出被预测值的均数、协方差阵即相关阵。

5、“使用所有定量变量”:所有的定量变量均参与估计,系统默认。
“选择变量”:用户自己选择变量,选择相关的变量作为“预测变量(R)”、“被预测变量(D)”。

6、EM:正太分布是系统默认的;混合正太分布,两个分布混合比例,在0-1之间,标准差的比值,取值大于0,余下的值用户自己定义;假定服从t分布,自由度用户自己定义。最大迭代次数为系统默认25。
回归:四个选项中选择一个作为回归模型中的误差项,系统默认随机抽取未缺失数据的残差作误差项。


1、调出相关操作界面。其数据的处理方法大致都是用变量的集中位置指标来替代缺失值,主要适合于完全随机缺失的资料,若不是完全随机的,得用“缺失值分析”模块分析缺失数据。

2、名称:给替代后变量命名。
方法:给出了5中缺失值的替代方法。

3、“附(邻)近点的跨度”:系统默认的是2,即缺失值上下两个观察值作为范围。若选择“全部”,即将所有的观察值作为临近点。

1、共计109例,给出缺失数量、缺失率、均值、标准差。
“T检验”:以行变量观察,按照“calories”缺失与否将数值分成两组,其观察值有75例,其中变量“lit_male”、“lit_fema”不缺有59例,缺失的有26例;由独立样本T检验,其中的分别是0.024和0.016,都小于显著性水平0.05,说明“calories”变量不是完全随机缺失的,与变量“lit_male”、“lit_fema”的大小有关。观察同理知变量“lit_male”、“lit_fema”缺失也不是完全随机的,与变量“calories”的大小有关。
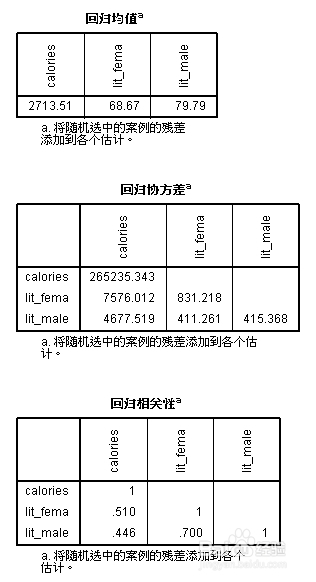
分别给出均值、标准差的原始数据、EM及回归方法的估计值。



2、给出未缺失数、未缺失率、缺失率,以及各为缺失数在各个值中的分布,如其中75例未缺失,未缺失率68.8%=75/109。
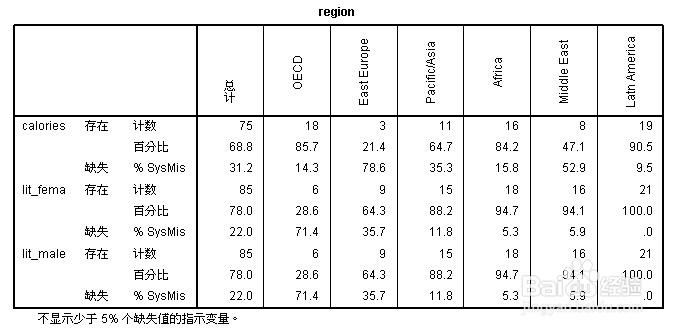
对仅有缺失值的观察单位描述缺失情况,图片有限,只给出部分数据,Pacific/Asia地区只有一个变量“calories”缺失,即国家“Afghanistan”;观察单位和变量均按缺失方式所占比例由小到大排列。
用“x”表示缺失,缺失率小于1%的缺失方式不予显示,59例数据中4个变量均不缺失,26例数据只缺变量“calories”,此26例数据的分布在“Region”中已全部给出。


3、分别是两种方法的结果展示:显示两两变量均未缺失的匹配系数,对角线上的数值为单变量未缺失例数,不是对角线上的则是两个变量匹配都不缺失的例数。
结果中都给出均值、协方差、相关性的数值。