1、本人之前抓取网页上的数据,都是httpwebrequest方法获取网页的html,通过浏览器的调试功能,找到对应元素的关键词。然后根据获取的内容去解析里面的自己需要的数据。

2、由于自己比较懒,一直没有去学正则表达式,所以解析只能用字符串处理的方法来做。用indexOf、replace、trim、substring、split等方法来对html进行处理,最终得到自己想要的内容。

3、但是这样做的话,非常花时间,而且很容易出错。于是,本人就在摸痕网上找了一种可以快速抓取数据的方法,那就是使用HtmlAgilityPack开源项目。
4、具体使用方法如下:
首先,从NuGet中搜索HtmlAgilityPack,并将其安装到项目中。


5、然后将dll引入到项目之中。

6、在下面这段代码中,我们用简单的几句就实现了从某个网页获取html,并且获取这个页面中的所有样式为lists_bigimg_right的div,然后通过遍历lists_bigimg_right,轻松获得了其中的名称、链接地址和说明三项内容。具体调用代码如下:

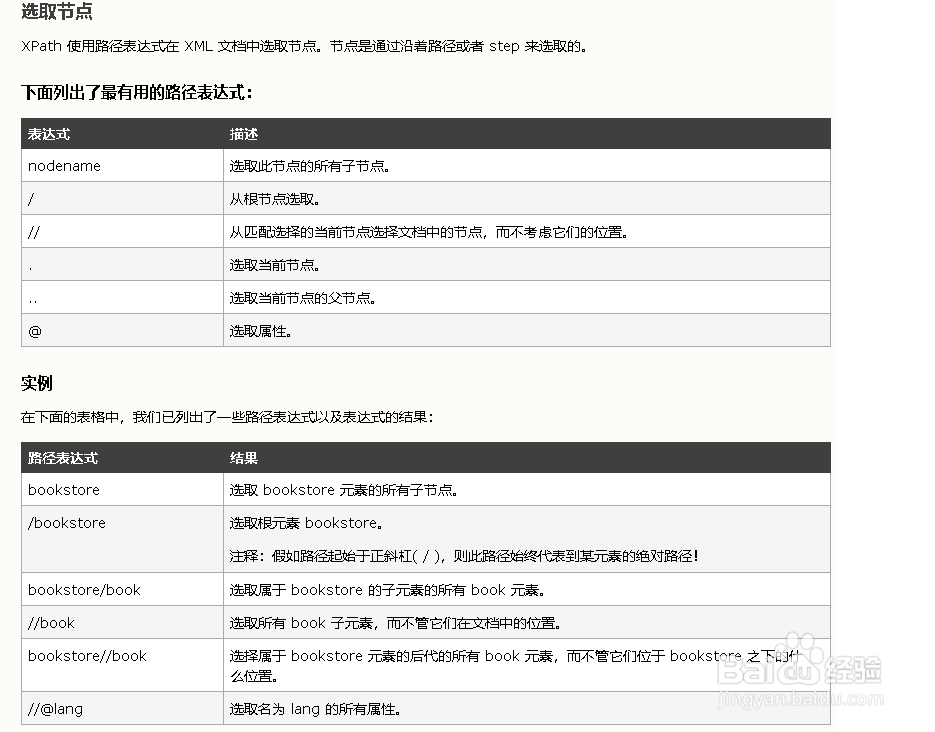
7、在使用HtmlAgilityPack之前,驼羞我们需要先了解它使用的语法,它使用的是xpath的语篇辞牺法,在浏览器搜索就可以得到相关的资料。使用HtmlAgilityPack可以大大提高抓取数据的准确性和抓取代码的编写速度。