1、首先我们需要一个表达谱数据的csv文件表。这些基因表达数据一般是在实验结束之后就会产生,是我们分析的源文件。
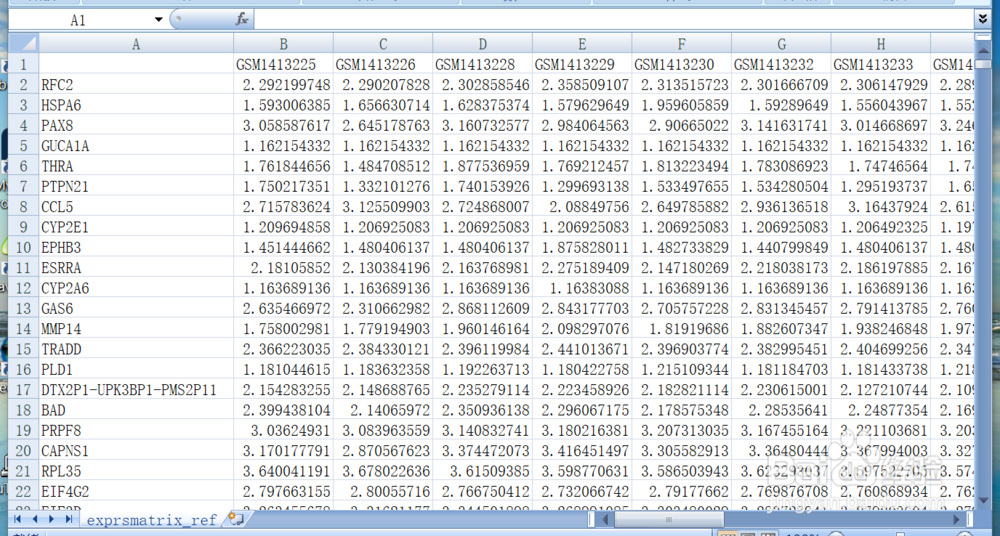
表达谱的格式为:
文件的A1单元格留白;
文件的第一行,写的是样本的唯一识别号,这个识别号可以自行指定,但请确保每个样本为一列且识别号都不同。
文件的第一列(A列),写的是基因简称,每个基因在HGNC网站的列表中都有且唯一。
数据格式如图所示:
2、其次我帽侵帮们需要一个记录着表达谱数据的来源和分组的csv文件表。
这一个csv文件记录宿罩着每一个样本的分组和其他信息。
分组信息表的格式为:
文件的A1单元格留白;
文件的第一列(A列),写的是样本的唯一识别号,这个识别号与表达谱数据表国游中的样本识别号一一对应。
文件的第一行则记录着对应的分组信息,并且分组信息一般命名为groups。
数据格式如图所示:

1、登录基因云馆,右上角点登录系统。输入账号密码进行登录。没有账号可以快速免费注册一个。

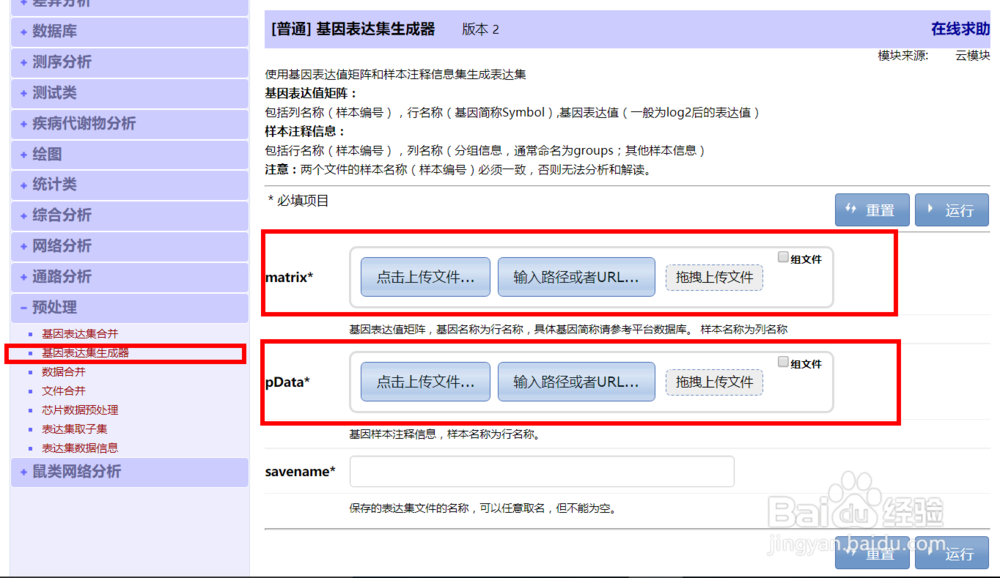
2、右侧选择 “预处理 > 表达集生成器”。
将上一步准备好的文件“表达谱数据的csv表文件”放入matrix;
“表达谱分组信息的csv表文件”放入pData;
最后填写一个saveName表示保存文件的文件名。
点击运行

3、生成与步骤2中的saveName填写的文件名对应的RData数据文件就可以进行后续的差异分析了。
同时,最好点击eSet_create.html报告查看生成的文件的简要信息。

1、右侧选择“差异分析 > 差异基因分析”;
在inputset*栏目里放入上一步生成的RData,剩余参数如下选择。
logFC代表倍增关系,一般是1-2,这里请选择1,如果差异基因过少可以适当降低;
pvalue代表p值,一般选择0.05,这里即选择0.05,如果差异基因过多可以适当降低;
genenamesets代表要单独显示表达变化的基因,这里填写可以 AHNAK2;
点击“运行”进行分析。

2、分析时间长度约为1-2分钟;
点击结果页面的DEG_GENE.html链接,查看结果报告。
差异基因的结果也就做出来了。你也可以试试其他参数,获得理想的结果。

