1、ElasticSearch 5.0版本前相关性判断及打分使用的算法是 TF-IDF ,5.0 版本以后使用的是 BM25 算法。
TF-IDF : Term Frequency, Inverse Document Frequency 即词频和逆文档频率,TF= 词项在文档出现次数/该文档总字数,IDF= log(索引文档总数量/词项出现的文档数量),简单来说,TF-IDF得分计算公式为:
文档得分 = TF(t) * IDF(t) * boost(t) * norm(t)
t 即查询串中每个词项,boost函数是ES提供的分数调整函数,norm函数根据文档长短返回一个值(文档短对应的值大)。
BM25 : 整体而言就是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大,BM25 针对针对这点进行来优化,随着TF(t) 的逐步加大,该算法的返回值会趋于一个数值。
图示,为索引指定自定义的相关性算法。

2、使用 explain 查看搜索相关性分数的计算过程
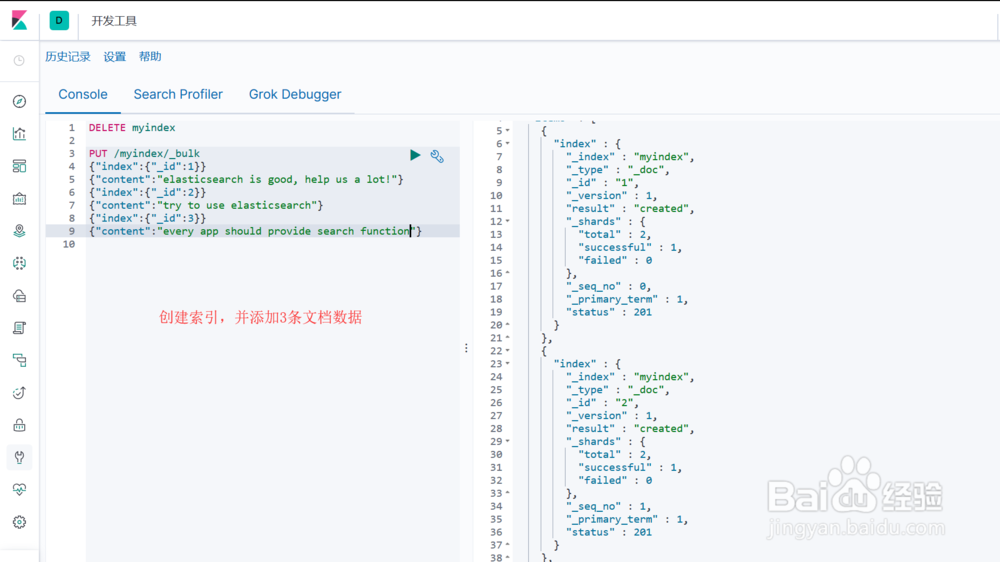
图1示:构建索引并添加3条文档信息
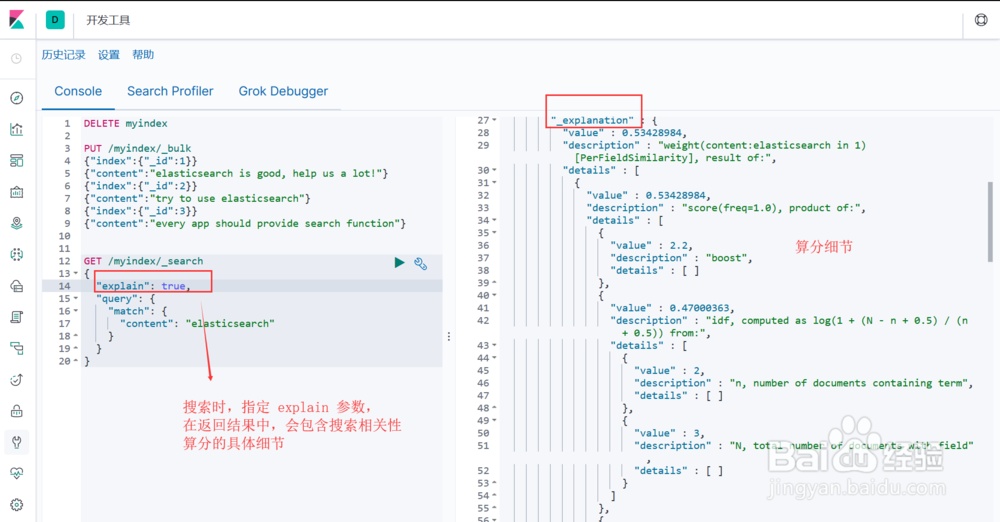
图2示:搜索时,指定 explain 参数,在返回结果中包含相关性分数的计算细节
3、默认相关性算分排序初体验
还是上面的索引和文档数据,查询 elasticsearch , 返回结果中,文档2获取的分数高于文档1(图示,文档2排在文档1前面),从上述公式中可以发现,导致这种算分差异就在于文档2的长度短于文档1。

4、通过 boosting query 嵌套搜索修改内层搜索结果的相关性得分
先看一下 boosting query 嵌套搜索的语法:
GET /myindex/_search
{
"query": {
"boosting": {
"positive": {
嵌套子查询
},
"negative": {
嵌套子查询
}
,
"negative_boost": 调整权重
}
}
}
boosting 嵌套查询以 positive 下的子查询来获取返回结果,negative 中的子查询对上述结果的相关性打分进行调整,通过 negative_boost 参数指定的值:
升权(>1), 降权(>0 and <1), 减分(<0)
5、通过 boosting query 嵌套term查询,降权处理相关性得分
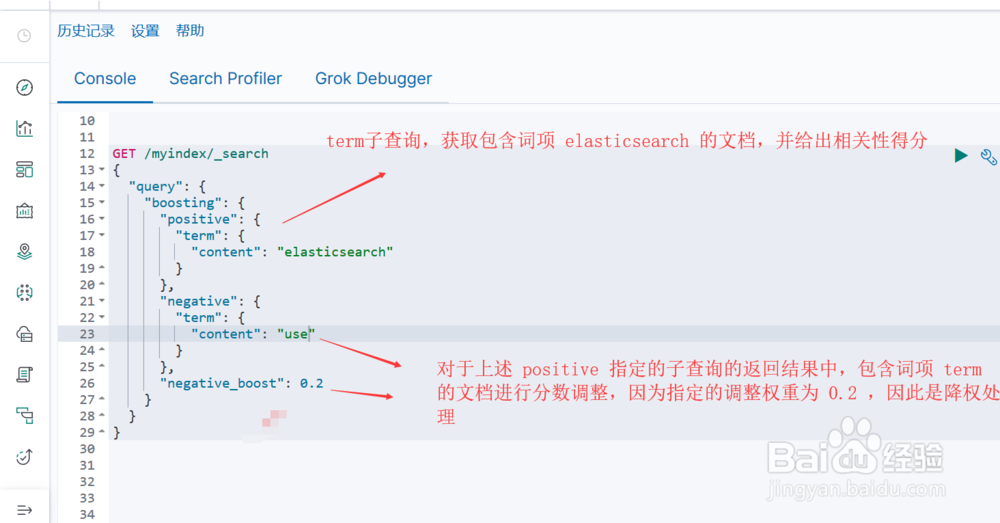
图1示,boosting query 中的 positive 下的 term 子查询获取包含词项 elasticsearch 的文档并给出相关性得分,negative下的 term 子查询对包含词项 use 的文档的得分进行降权调整(降权参数为 0.2 )
图2示,查询结果,相比未进行调整,文档1的相关性得分高于文档2的得分

6、通过 boosting query 嵌套match查询,升权相关性得分
图示,boosting query 中的 positive 下的 match子查询获取包含词项 elasticsearch 或者 good 的文档并给出相关性得分,negative下的 match子查询对包含词项 use 的文档的得分进行升权调整(升权参数为 2.5),查询结果中,文档2的相关性得分高于文档1的得分
