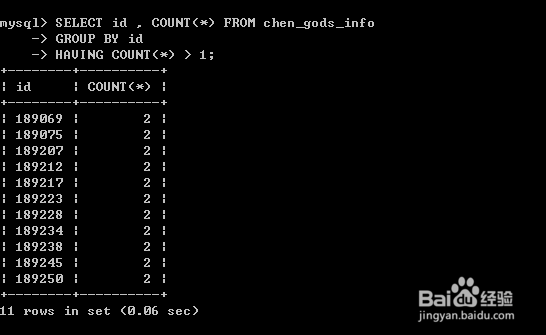
1、假如我有一张表,
数据在某一个字段有重复(比如我现在的ID重复了)
那么我使用:
SELECT id,COUNT(*) FROM table
GROUP BY id
HAVING COUNT(*) > 1;
语句 意思:
从读下来是 查询id,并且统计行数
数据来自 table表
按照id列进行分组(如果我们按照性别分组,那么现出来的数据只有"男 女")
当统计完成后,count的结果大于1才予以显示
简单的来说就是根据id列进行分组统计,大于1的所有数据显示出来:
2、使用DELETE 配合 IN 进行删除(IN 如果里面是SQL语句,请尽量不要用于线上程序):
DELETE FROM table WHERE
id IN (
SELECT id FROM (
SELECT id,COUNT(*) FROM table
GROUP BY id
HAVING COUNT(*) > 1
) AS a
) LIMIT 1;