1、第一步,在已创建好的python文件中,导入numpy和pandas模块;然后使用list和zip,如下图所示:
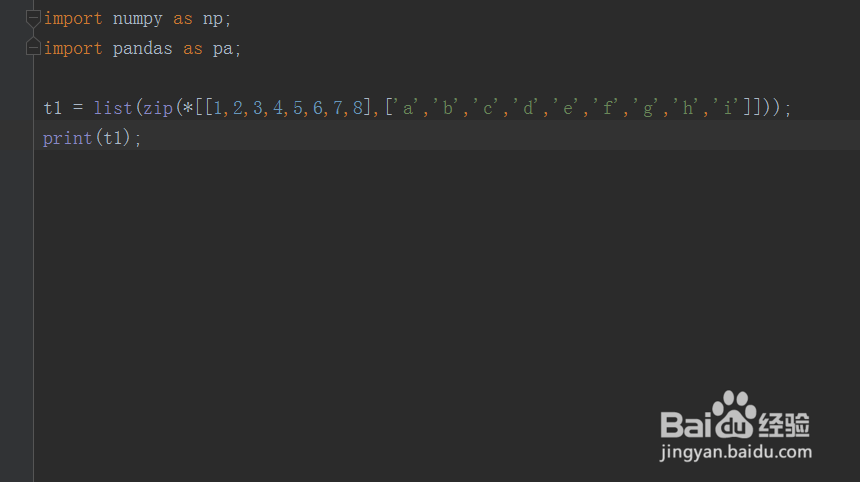
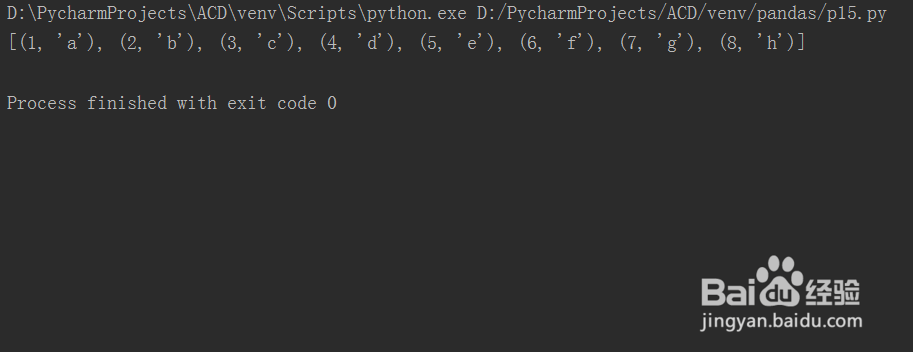
2、第二步,保存代码并运行python文件,发现生成的元素一对一生成,如下图所示:
3、第三步,调用pandas模块中的MultiIndex.from_tuples()方法,如下图所示:

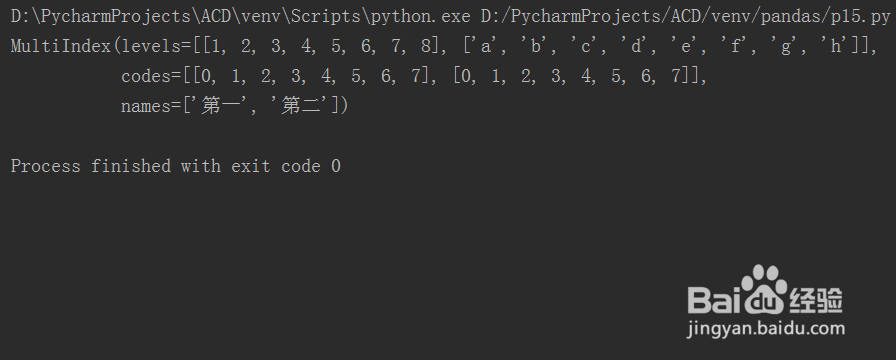
4、第四步,再次保存代码并运行文件,发现levels、codes、names几个属性,如下图所示:
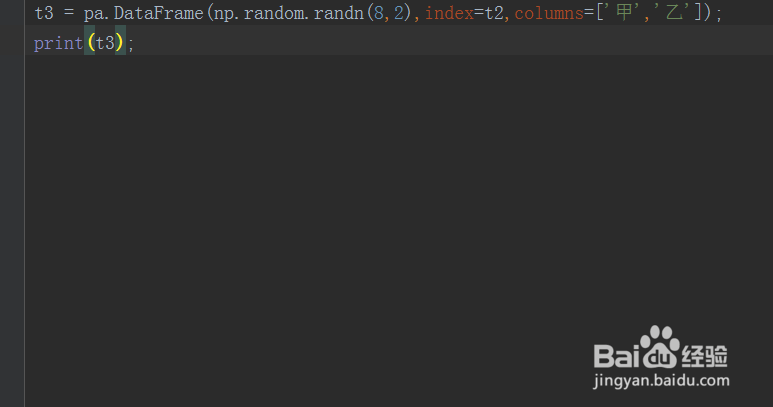
5、第五步,接着使用DataFrame()方法创建矩阵,index使用t2,如下图所示:
6、第六步,再次保存代码并运行这个文件,发现第一行是第一、第二、甲和乙,如下图所示:
