1、先安装requests包,打开电脑运行输入‘cmd’,在命令行窗口输入
‘pip install requests’

2、打开Python开发工具IDLE,新建‘request.py’文件,并写代码如下:
import requests
r = requests.get('http://www.baidu.com')
print (type(r))
print (r.text)

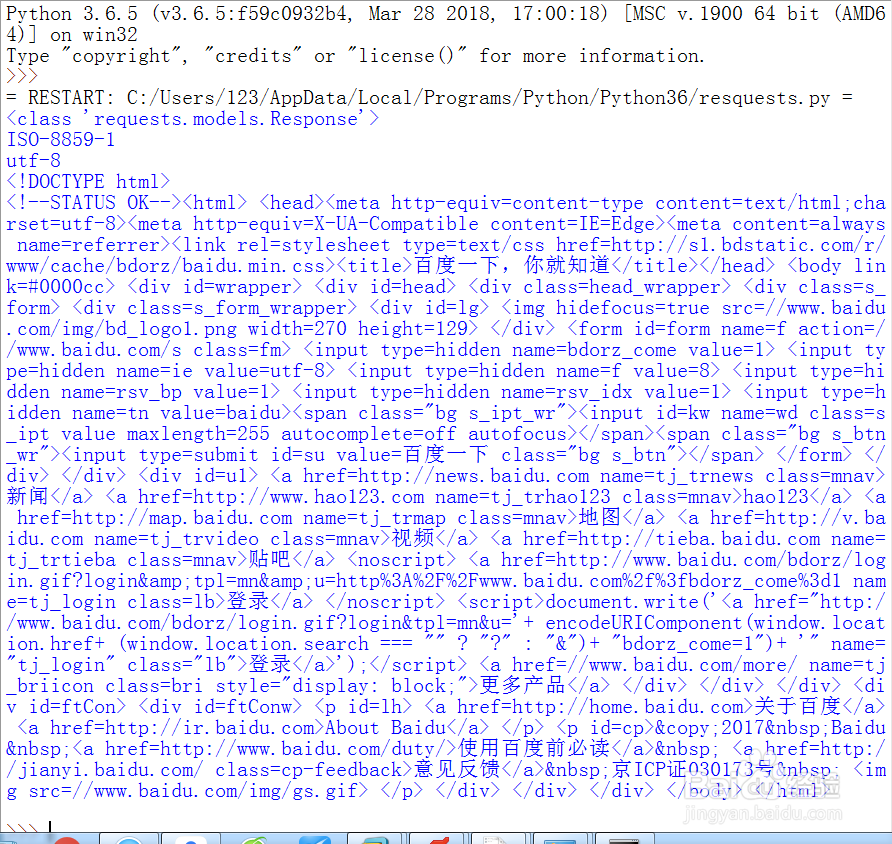
3、F5运行程序,打印出信息如图。r = requests.get('http://www.baidu.com'),
r是requests.models.Response的对象。r.text是其网页内容。

4、这里有乱码,查看网页发现charset的编码是‘utf-8’,但是‘utf-8’不会乱码,我们打印Response r 的编码。代码如下:
import requests
r = requests.get('http://www.baidu.com/')
print (type(r))
print (r.encoding)
print (r.text)

5、F5运行程序,打印出:ISO-8859-1为其编码方式,这就是问题所在,继续改写代码如下:
import requests
r = requests.get('http://www.baidu.com/')
print (type(r))
print (r.encoding)
print (r.apparent_encoding)
print ((r.text.encode(r.encoding).decode(r.apparent_encoding)))
r.apparent_encoding是通过内容分析出的编码,这里是utf8编码


6、F5运行程序,网页内容没有乱码了,通过r.apparent_encoding即utf-8解码就行了。一般网页通过这种方式都能解码正常