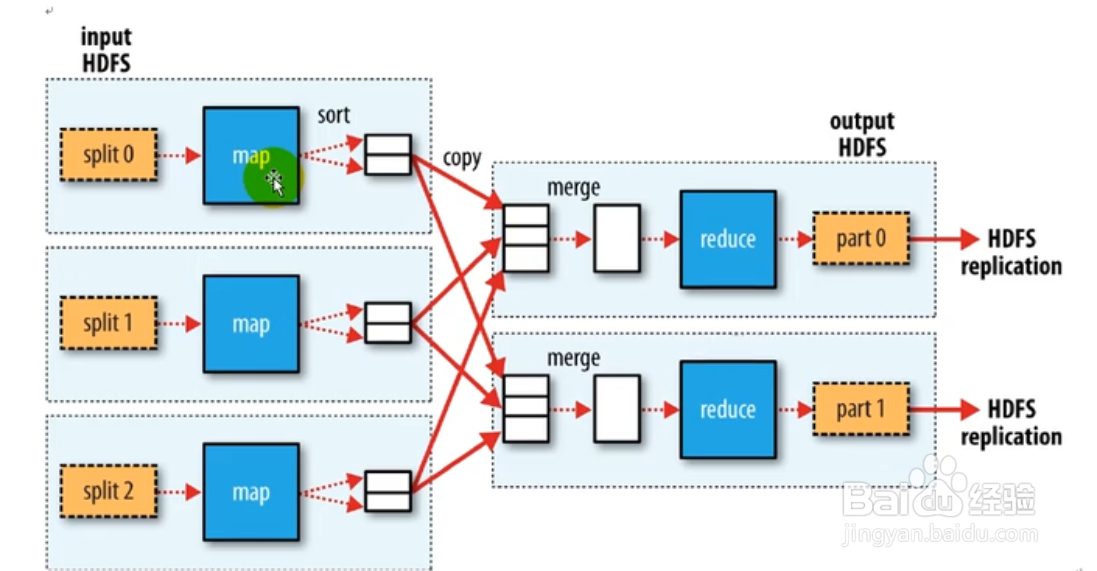
1、每个block会有map任务,block逻辑切分为切片,每个切片对应一个map任务,默认一个block,一个切片,一个map任务。map默认按行读取数据,组成键值对<字节偏移量,"行数据">,然后计算输出,新的键值对<key,value,partition>。
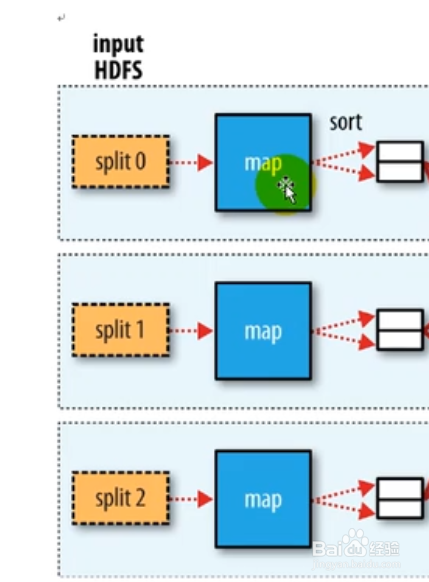
2、map任务会将上面计算输出的键值对(这里可以设置combinClass,在map端对数据进行压缩,减少落磁盘的网络IO处理),写到环形缓冲区,默认缓冲区大小是100MB,阈值80%,也就是缓冲达到了80%,就会落地磁盘溢写小文件,该文件已经按分区号,key进行排序

3、默认小文件数量达到了三个,就会进行归并,归并的新文件也是按分区号,key排序好了的。map任务完成后,它的输出文件会被按照http get的方式下载到reduce任务的主机。
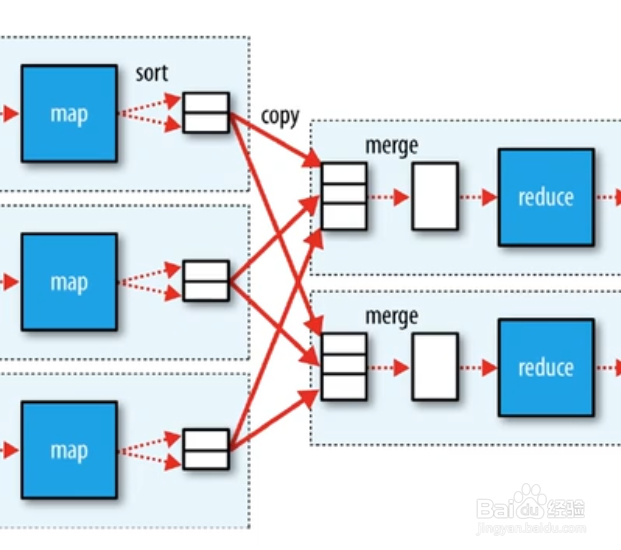
4、等map所有任务结束,并且洗牌结束,每个reduce任务获取对应数据,reduce任务开始处理任务。如果时间充裕,reduce会对洗牌后的数据,进行归并写磁盘,如果没有时间,就只归并大文件,直接交给reduce任务进行迭代处理
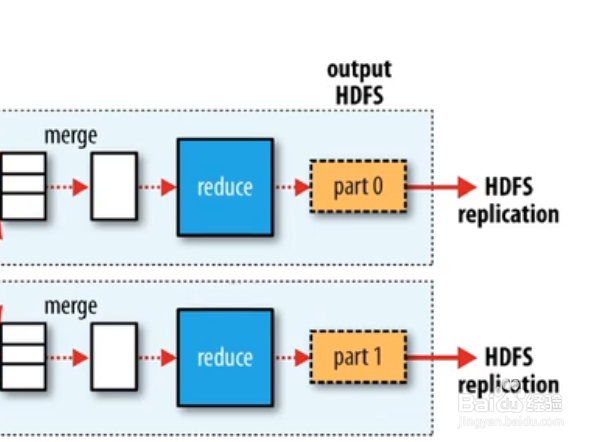
5、reduce按照key分组,每组执行一次reduce方法,该方法迭代计算,将结果写入到hdfs,reduce是并发处理的