1、在本次教程中,我们采用pycharm进行编程。首先了解一下jieba库,jieba库是优秀的中文分词第三方库。
jeiba库分词的原理:jieba分词依靠中文词库,利用一个中文词库,确定中文字符之间的关联概率,中文字符间概率大的组成词组,形成分词结果。
2、安装jieba库:
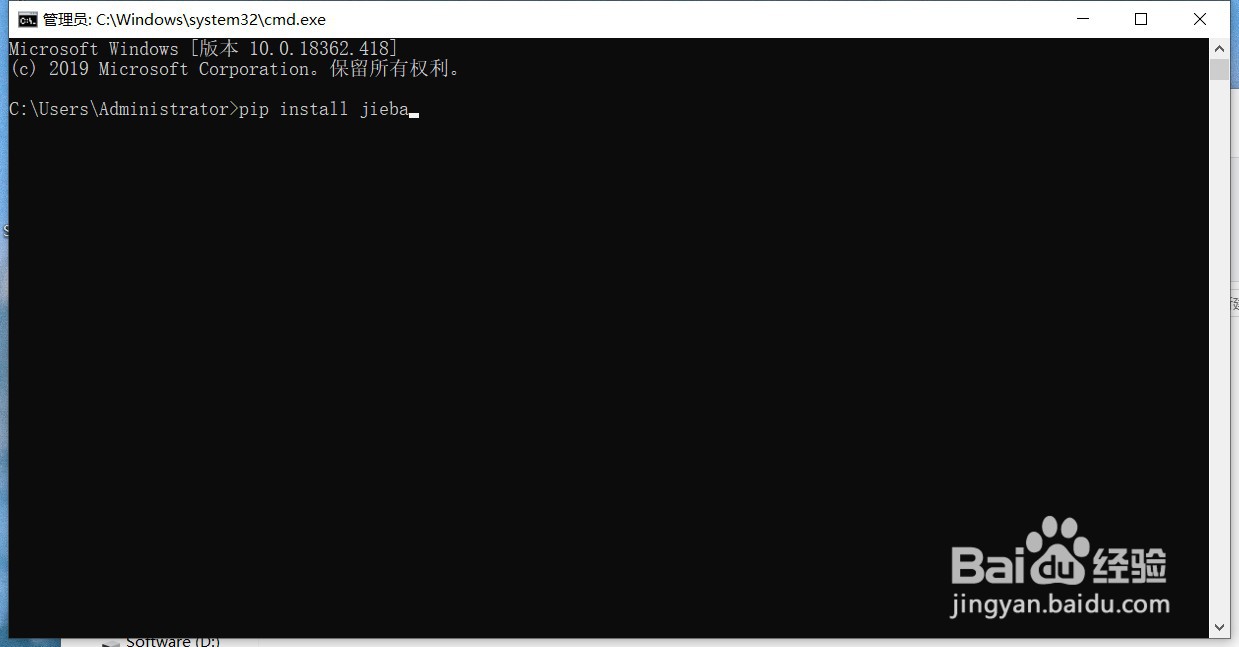
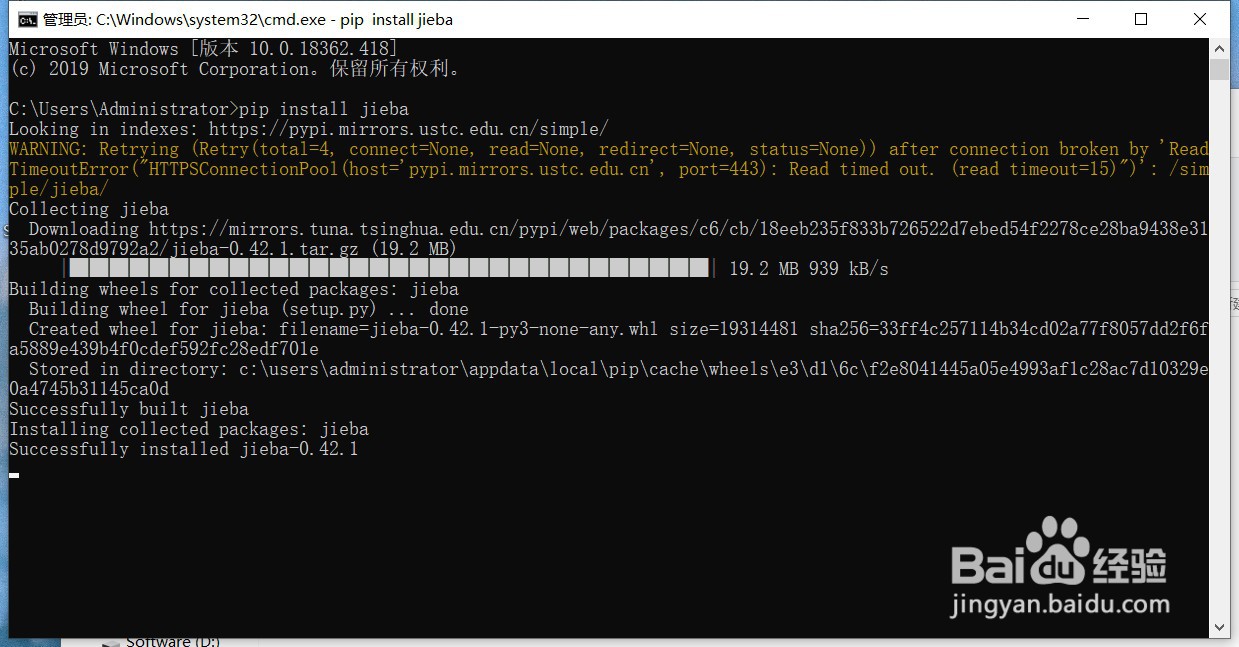
在桌面摁下“win”+“r”,输入cmd,接着输入“pip install jieba”,等待命令行运行完成,当出现“successful”就说明jieba库已经安装成功了。


3、jieba库有三种分词模式,精确模式、全模式、搜索引擎模式。
精确模式:把文本精确地且分开,不存在冗余单词。
全模式:把文本中所有可能的词语都扫描出来,词与词之间存在重复部分,有冗余。
搜索引擎模式:在精确模式基础上,对长词再次切分。
4、jieba库常用函数:
1、jieba.lcut(s) 精确模式,返回一个列表类型的分词结果
2、jieba.lcut(s, cut_all=True) 全模式,返回一个列表类型的分词结果,有冗余
3、jeiba.lcut_for_search(s) 搜索引擎模式,返回一个列表类型的分词结果,存在冗余
(其他函数操作可以参照官方文档)
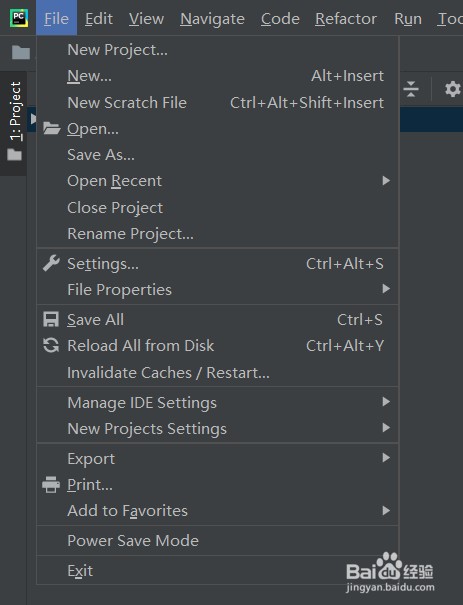
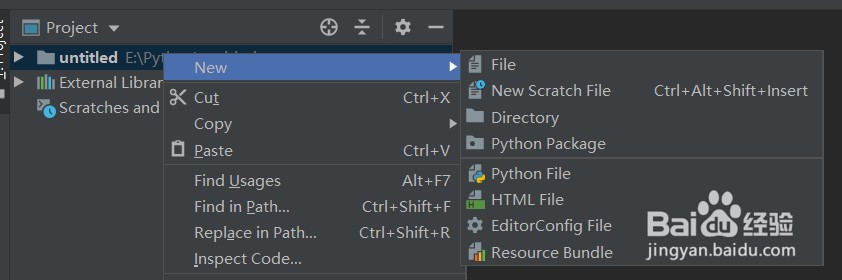
5、打开pycharm,点击左上角“File”-“New Project”新建一个项目(图1),选择任意目录,选择python 3.8解释器,点击“cerate”,在project处右键点击“New”-“Python File”,任意取一个名字回车


6、在新建的py文件中输入:
import jieba
txt = "把文本精确地分开,不存在冗余单词"
# 精确模式
words_lcut = jieba.lcut(txt)
print(words_lcut)
# 全模式
words_lcut_all = jieba.lcut(txt, cut_all=True)
print(words_lcut_all)
# 搜索引擎模式
words_lcut_search = jieba.lcut_for_search(txt)
print(words_lcut_search)
代码即可实现对字符串txt的分词