1、【确定方案】
将硬盘连接至安全的操作环境中(不加载盘符,不自动写数据,保证完全只读),发现文件系统底层上完全正常,但数据区全部错误。以一个PDF文件为例,在WINHEX中打开时如下图:

2、一个正常的PDF文件,二进制结构一定是以0x46445025(即ASCII的“%PDF”)做为开头标志。这个文件的开头以0x71736712开始。两者比较,显然是一种异或转换,通过计算,两者相差(异或)0x37。观察本PDF文件的尾部,发现同样做了篡改。
于是,在WINHEX中选中文件所有内容,对选中块以0x37做字节异或(xor):
保存出来后,打开,文件正常。


3、接下来对其他文件做分析,发现篡改的算法均是全部文件对某个值xor,但此值不确定,按字节概率计算,应该有256种可能,加上文件数量及类型众多,显然不能手动进行修正。需要分析其xor加数的生成规律。
分析过程如下:
1、推断是否与路径相关:在同一路径下打开不同的文件分析篡改的异或加数,发现不尽相同,排除。
2、推断是否与文件名称相关:查找所有文件,按名称排序,找到相同文件名称但大小不同的文件,打开后分析篡改的异或加数,发现不相同,排除。
3、推断是否与类型相关:找到同一类型的几个不同文件,分析篡改的异或加数,发现不相同,排除。
4、推断是否与存储的物理位置相关:在WINHEX中按不同文件起始位置进行分析篡改的异或加数,未发现相关性,排除。
5、推断是否与文件头部相关:查找头部相同的文件(有同一文件的不同更新,头部是相同的),进行分析,也排除。
6、推断尾部相关的可能性不大。(当然如果后面分析仍无法得到规律,则需返回此项再做验证)
7、推断是否与文件创建时间相关:分别查找相同创建时间、相同访问时间、相同最后一次访问时间的2个文件,进行分析,发现与此无关,排除。
8、推断是否与大小相关:简单验证后,未举出反例推翻,但需要完全证明与大小相关,同时要得到算法,需要有足够多的样本。
4、对是否与大小相关的验证:
首先通过命令方式打印所有文件的大小,WINDOWS很不擅长此操作,改用LINUX处理:
find ./ |xargs ls -ld 2>/dev/null|awk '{printf($5"\t\t"$9"\n");}' >../list.txt
之后用excel打开此列表文件,如下图:

5、因篡改的异或加数只有一个字节,故推断,如果与大小相关,极有可能是对文件大小mod 256后关系对应,于是在excel中计算所有文件大小值 的mod 256,如下图:

6、对mod 256的值进行排序,excel可能可以直接实现,不过,至少可以复制整列,再以数字方式粘贴:
排序后如图


7、对相同mod 256的文件进行篡改验证,未发现不符合规律者,基本断定篡改值与文件大小mod 256的值存在完全映射关系。
对所有可能做抽样分析后,得到篡改异或加数的生成规律:
至此,篡改算法得到,同时修正算法也自然就容易多了。
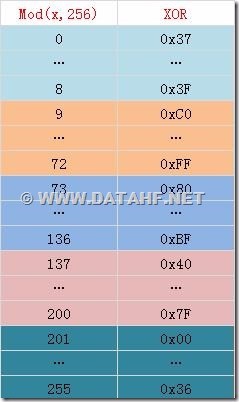
8、【解决方案】
通过VS2010下编写程序解决,修复程序源码如下:




9、【验证】
程序运行完成后,对文件进行抽检,无报错,为进一步确定可靠性,查找所有JPG文件,显示缩略图,无异常。

10、 查找所有doc文件,显示作者,标题(这两个信息是通过内容部分得到的),未发现异常(只是OS盗版的痕迹挺重,呵呵),至此,确定算法正确。数据恢复完成。
