1、导入import urllib.request

2、打开一个网址:resp=urllib.request.urlopen("http://www.baidu.com")
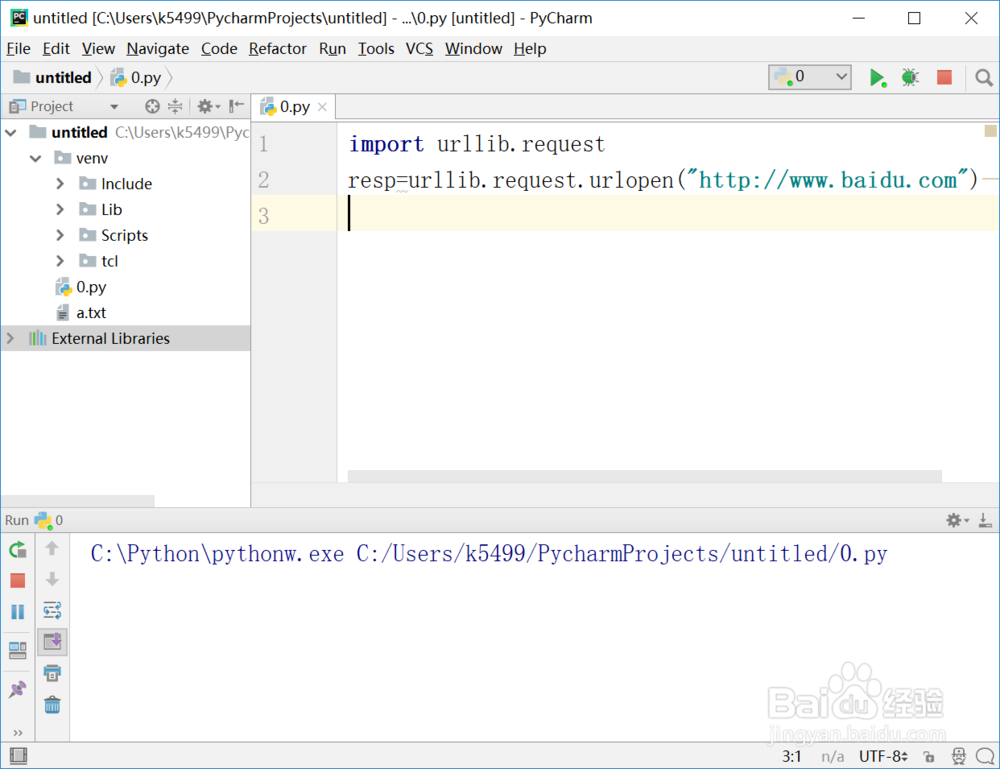
3、读取网页内容,然后把内容保存起来:str = resp.read()
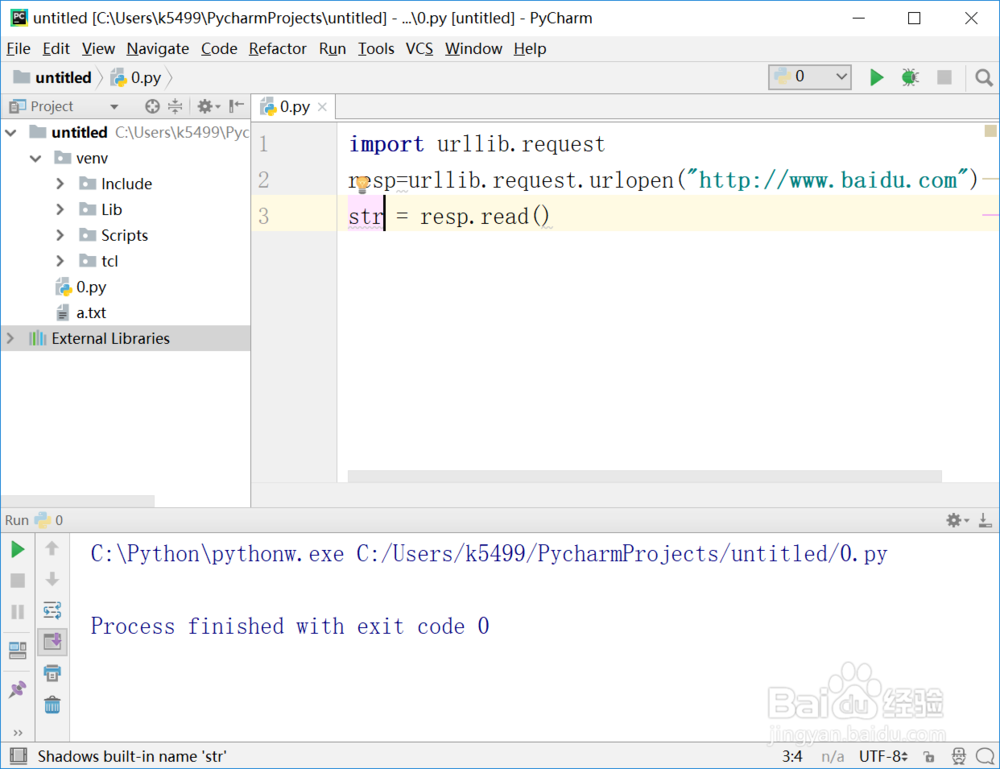
4、打印刚才读取的内容:print(str)
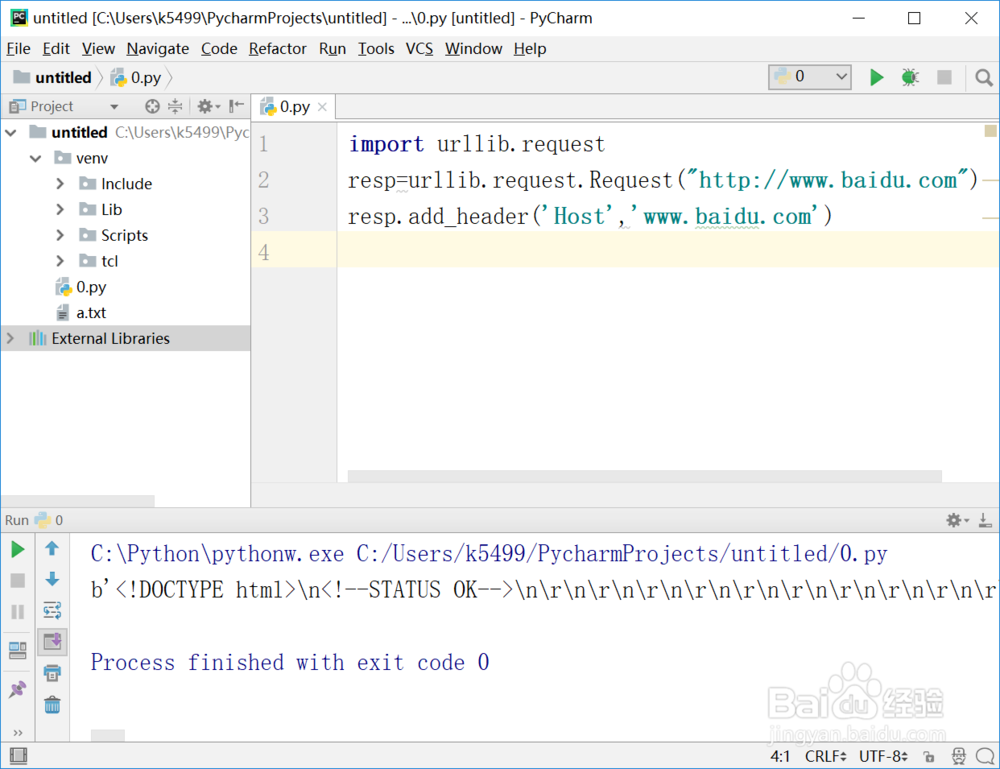
1、把上面的urlopen改成Request,如下:
resp=urllib.request.Request("http://www.baidu.com")

2、然后添加请求头,如下
resp.add_header('Host','www.baidu.com')
3、创建一个连接,上面的打开网址连接是一样的,只是把网址换成了Request对象
r = urllib.request.urlopen(resp)

4、然后读取网址,打印出来就可以了
