1、首先通过pip安装lxml模块。

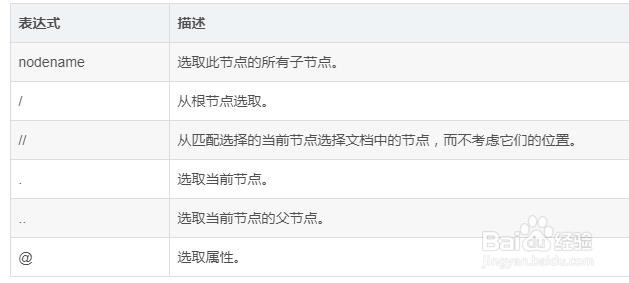
2、需要熟悉一下这些最有用的路径表达式
1、引入包:from lxml import etree

2、解析获得的网页:html = etree.HTML(要解析的网页或文本)

3、使用etree匹配获得要取得的内容,下面例子中,
xpath('//li[contains(@class,"sp")]/a/text()')
匹配的是class属性值包含sp的li节点下的超链接A的text值。
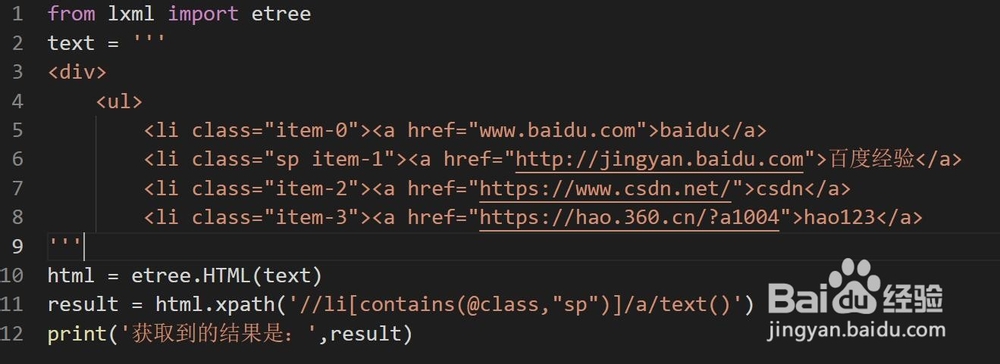
4、run查看结果。

1、首先通过pip安装lxml模块。
2、需要熟悉一下这些最有用的路径表达式
1、引入包:from lxml import etree
2、解析获得的网页:html = etree.HTML(要解析的网页或文本)
3、使用etree匹配获得要取得的内容,下面例子中,
xpath('//li[contains(@class,"sp")]/a/text()')
匹配的是class属性值包含sp的li节点下的超链接A的text值。
4、run查看结果。