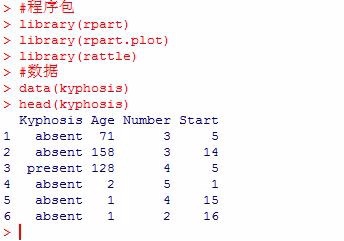
1、这里以R中自带的数据集kyphosis为例。根据Age、Number、Start三个变量对kyphosis进行分类。
#程序包
library(rpart)
library(rpart.plot)
library(rattle)
#数据
data(kyphosis)
head(kyphosis)
2、定义参数并建立模型。
#参数
control <- rpart.control(minsplit=10,
minbucket=5,
xval=10,cp=0.1)
#决策树模型
model<- rpart(Kyphosis ~ Age + Number + Start, data = kyphosis,
method="class",control=control,
parms = list(prior = c(0.6,0.4), split = "information"))

3、查看模型结果。summary可以查看模型的详细过程。
summary(model)
asRules(model)


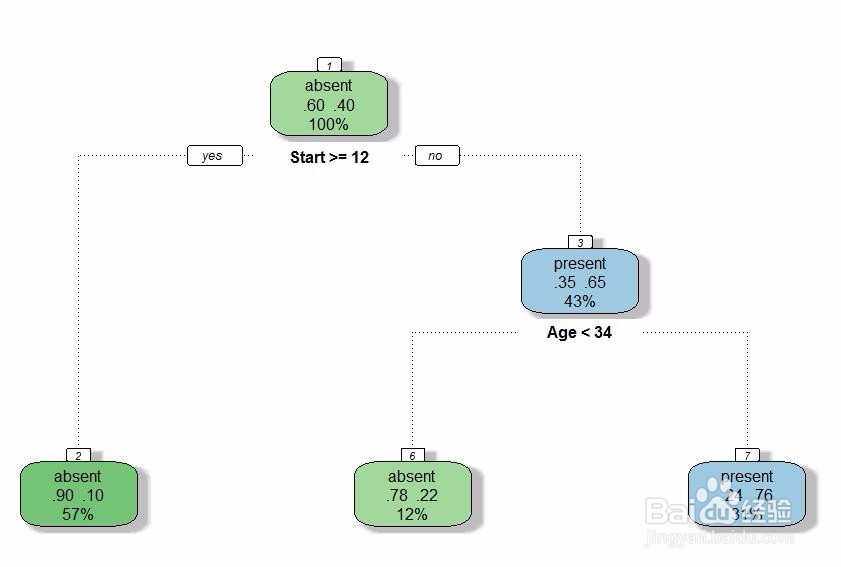
4、绘制决策树图。可以从图中看到每一类的观测数及占总数的比例。
fancyRpartPlot(model)
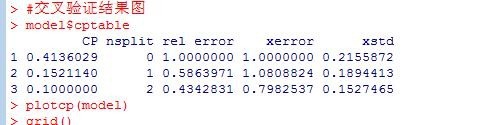
5、查看交叉验证结果,并绘图。
model$cptable
plotcp(model)
grid()
可以看到结果中有交叉验证的估计误差(“xerror”),以及标准误差(“xstd”),平均相对误差=xerror±xstd 。
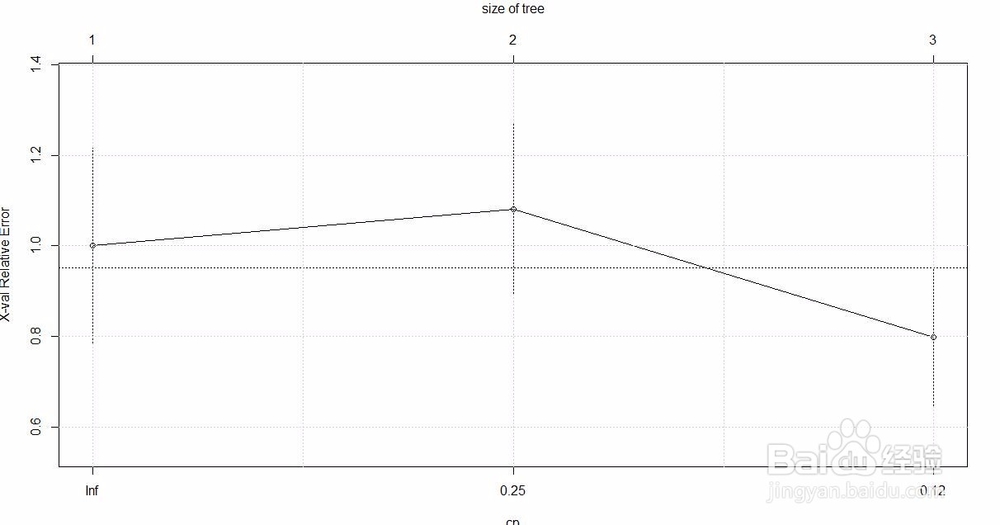
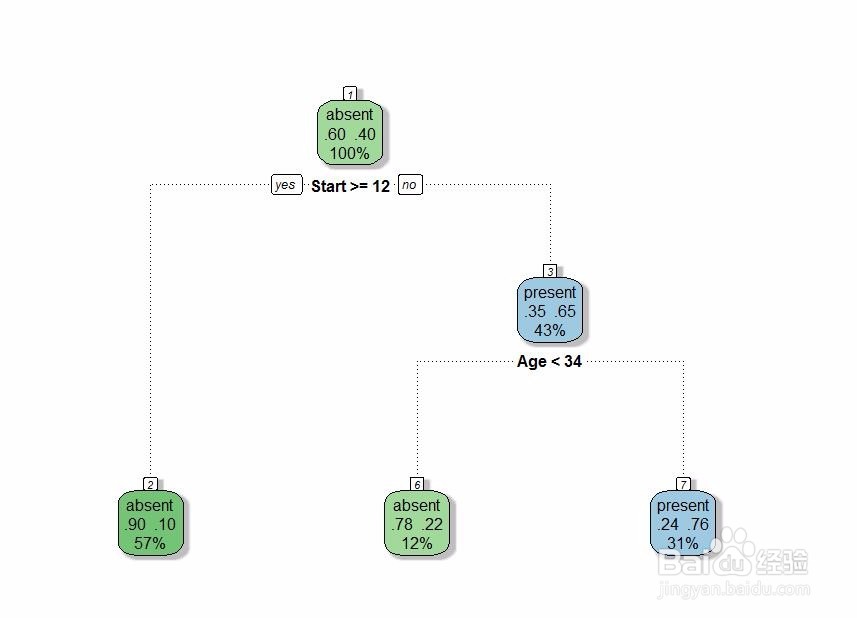
6、根据交叉验证结果,找出估计误差最小时的cp值,并重新建立模型。
#选择交叉验证的估计误差最小时对应的cp
xerr <-model$cptable[,"xerror"]
minxerr <- which.min(xerr)
mincp <-model$cptable[minxerr, "CP"]
#新模型
model.prune <- prune(model,cp=mincp)
fancyRpartPlot(model.prune)