1、聚类分析的描述




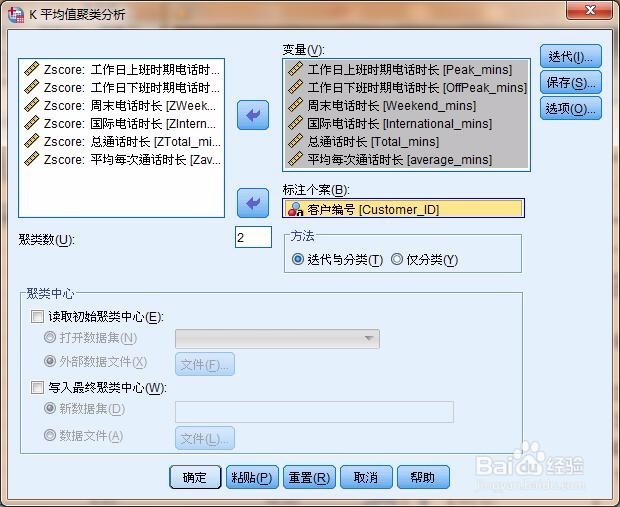
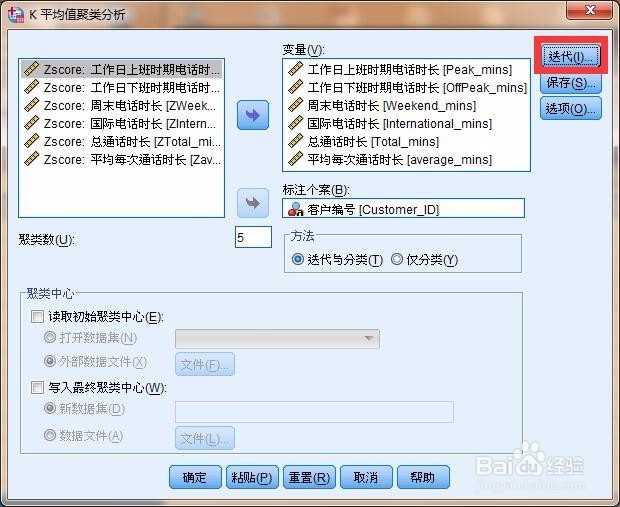
2、【分析】-【分类】-【k-平均值聚类】,进行相关参数的设置

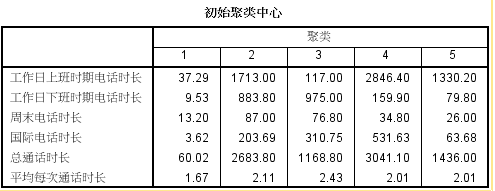
3、结果显示:spss从中挑选了几个个例
5个聚类中心选择了5个原始案例
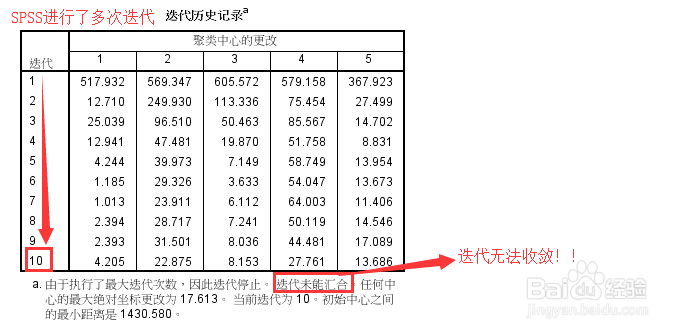
4、针对存在的问题,进行相关参数的设置,增加迭代次数。。足够的迭代后,已经收敛,但还存在一个问题是:各聚类的效果不明显

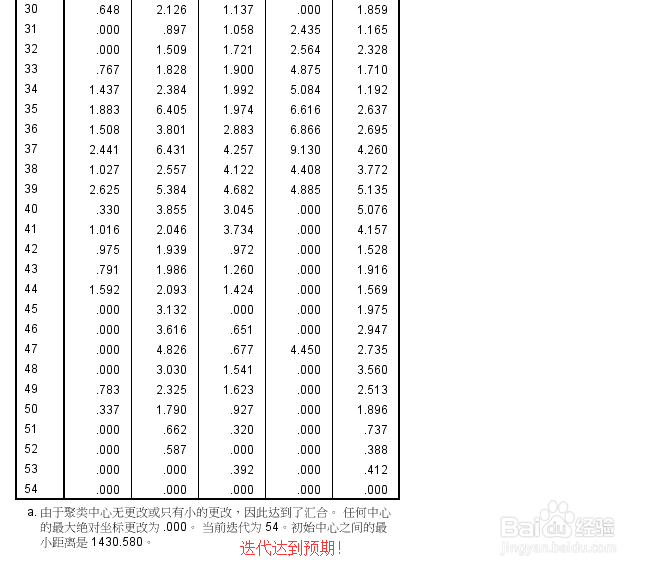

5、主要是原始数据中差别有点大

6、所以要对数据进行标准化,得到标准化后的结果。



7、利用标准化后的数据进行聚类分析

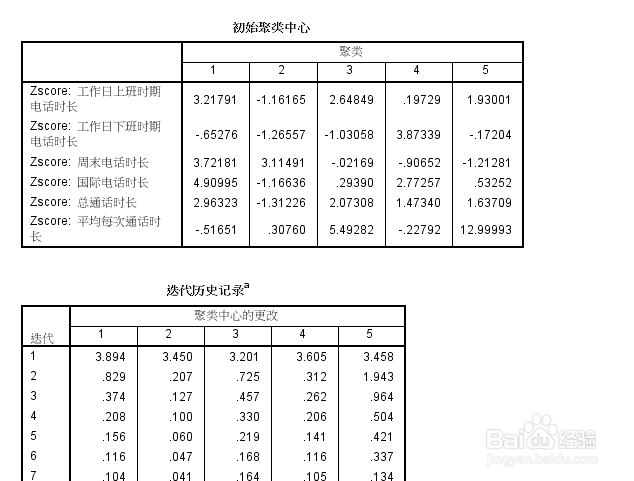
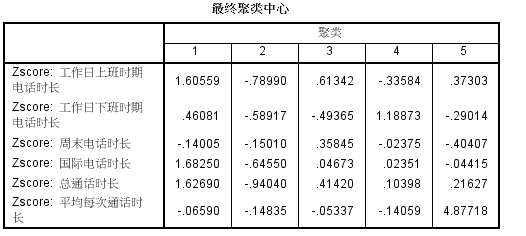
8、结果看起来比较别扭
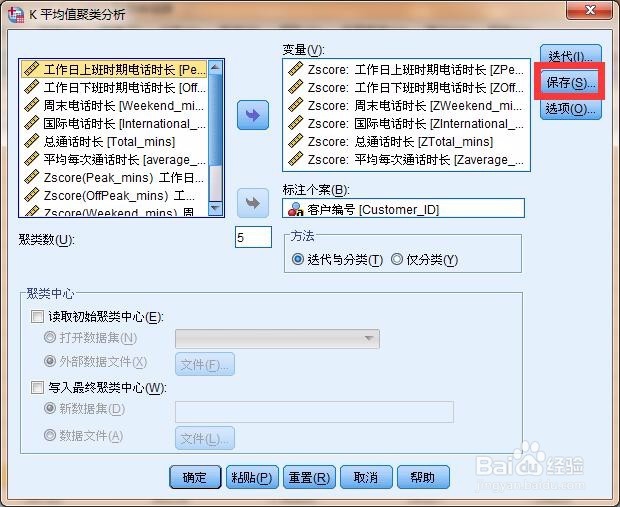
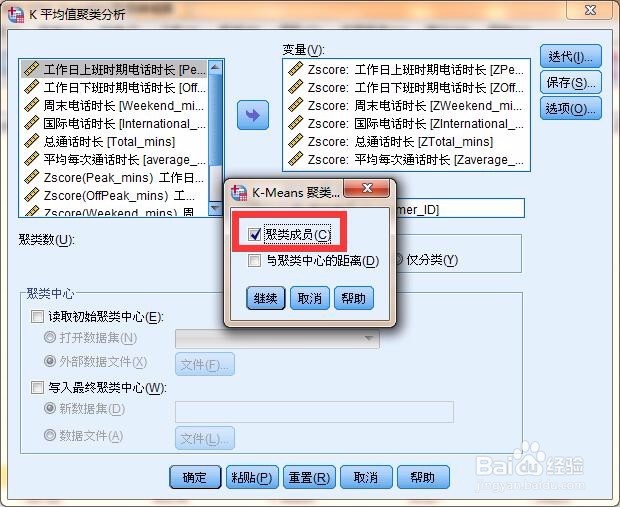

9、接着进行【分析】,【比较平均值】
3395个样本中有443个
1,2,3,4,5类各具有特点



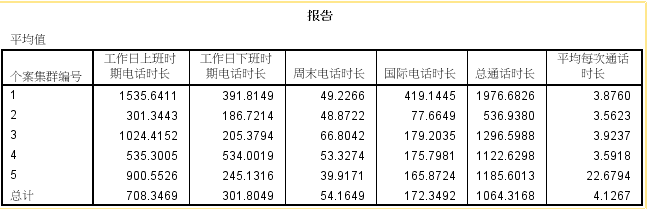
10、结果



11、对变量做聚类分析
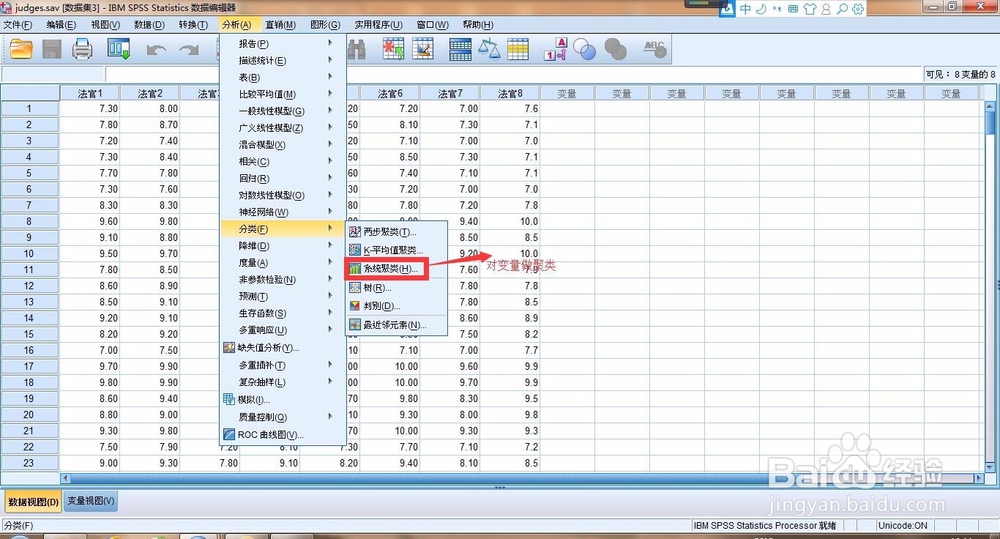
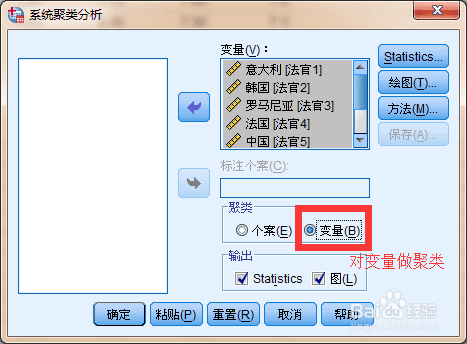
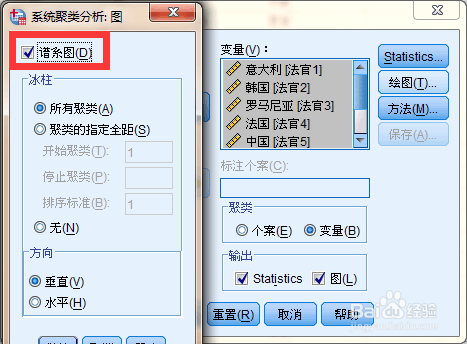
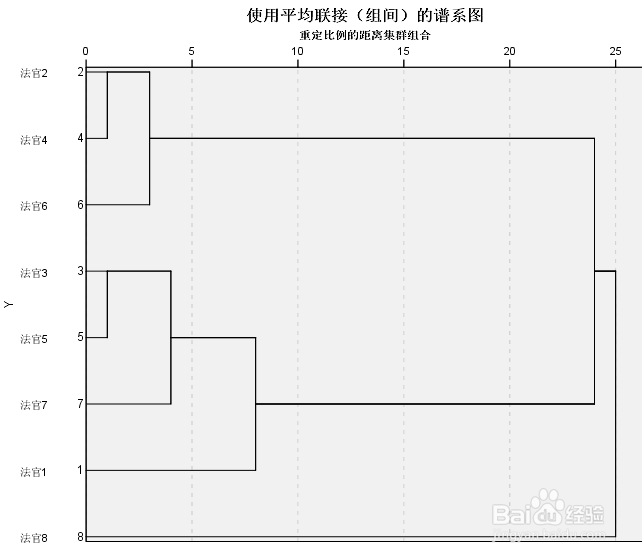
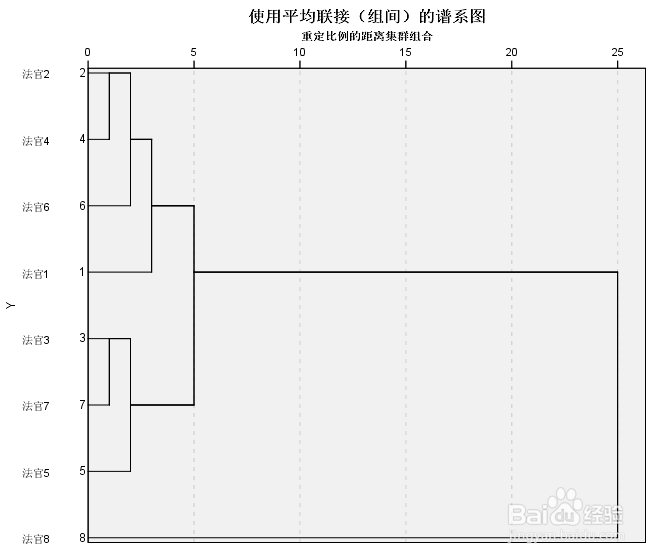
12、结果:
第二张图中的横轴“25”对应“凝聚计划”表系数(距离)中的最大值233.297依次换算即可
这个聚类结果不太合理
----------------------换方法

13、换方法
结果合理!
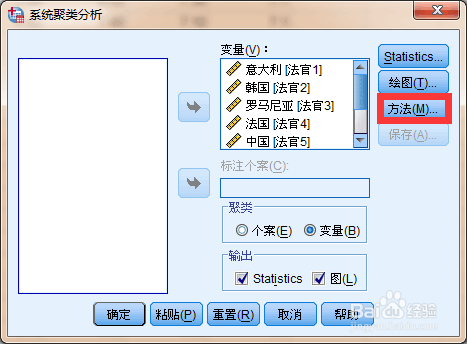

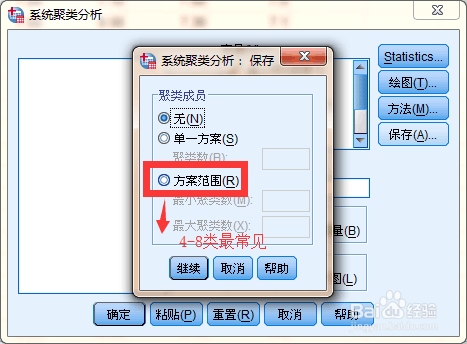
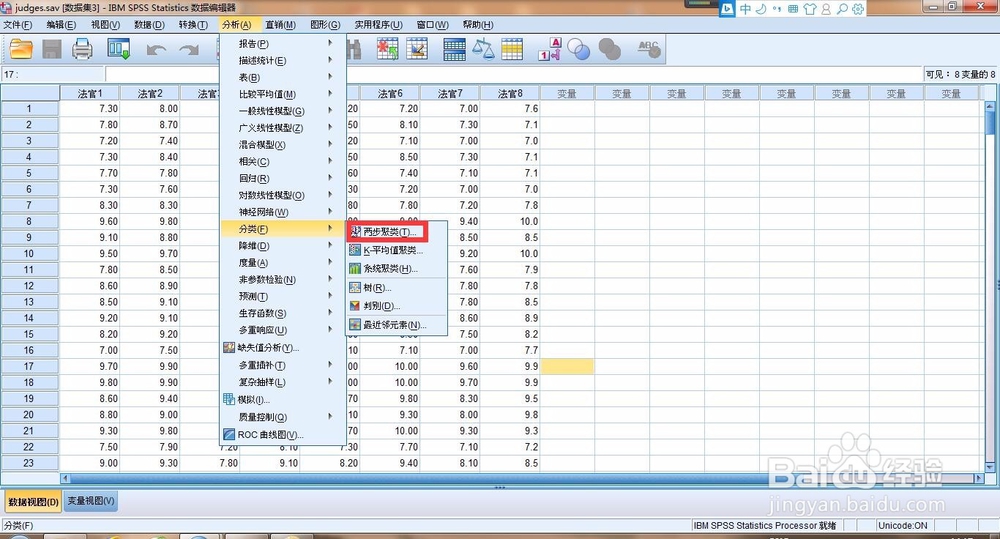
14、个案聚类,这个过程会自动处理缺失值,使得整体数据更加服从适用条件,也就是【两步聚类】


15、结果被 聚为两类

16、需要注意的事项:数据预处理:许多变量有强的共线性可以提取公因子,个别变量有共线性可以删除其中一个次要的变量,或者把它俩相加或平均组合成一个次要的。两步聚类可以自动处理异常值,把异常值单独归为一类。



17、其他方面

