1、1)上传并解压spark安装包
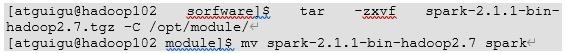
2、2)官方求P

3、(1)基本语法

4、(2)参数说明
--master 指定Master的地址;
--class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi);
--deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client);
--conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value” ;
application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
application-arguments: 传给main()方法的参数;
--executor-memory 1G 指定每个executor可用内存为1G;
--total-executor-cores 2 指定每个executor使用的cup核数为2个。
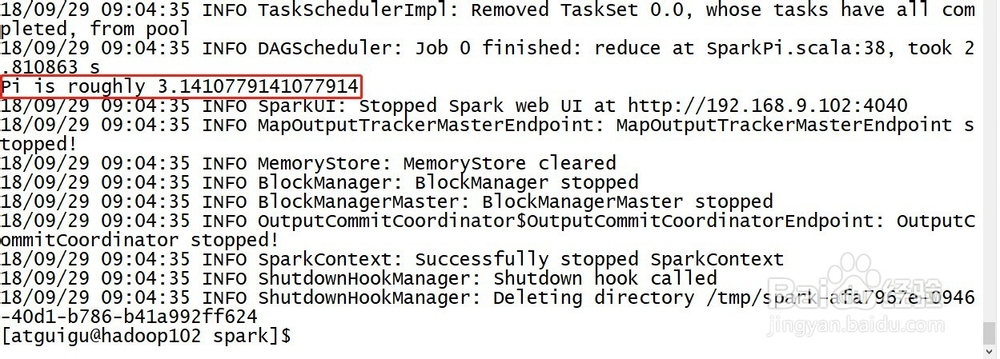
5、3)结果展示
该算法是利用蒙特·卡罗算法求PI
6、4)准备文件

7、在input下创建3个文件1.txt和2.txt,并输入以下内容

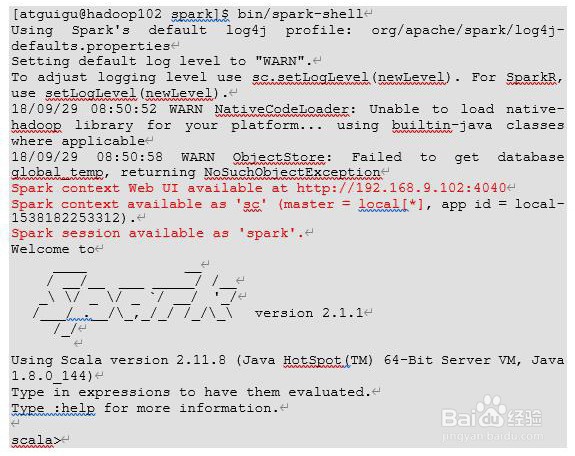
8、5)启动spark-shell
9、开启另一个CRD窗口

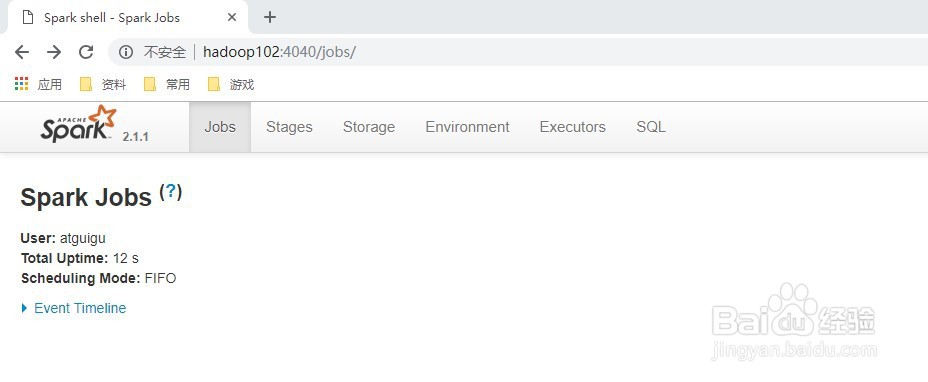
10、可登录hadoop102:4040查看程序运行
11、6)运行WordCount程序

12、可登录hadoop102:4040查看程序运行
