1、打开JUPYTER NOTEBOOK,新建一个空白的PY文档。

2、import re
首先引入必要的regular expression模块。

3、a = re.compile(r'.t')
a.findall('at the front of this product.')
这里用句号.来表示查找任何字符,但是只含一个字符。

4、a = re.compile(r'...t')
a.findall('at the front of this product.')
为了寻找多个字符,我们可以添加多个句号来表示。

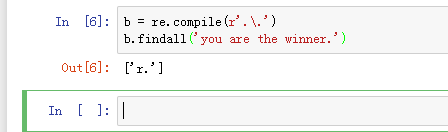
5、b = re.compile(r'.\.')
b.findall('you are the winner.')
如果要寻找真正的句号,而不是任意字符,可以用\来跳过功能。
6、c = re.compile(r'class:(.*)name:(.*)')
cc = c.search('class:First name:Peter')
cc.group(1)
cc.group(2)
.*是用来表示一部分任意字符,一般分组来表示选取会比较合适。

7、d = re.compile(r'.*')
d.findall('you are good man.')
如果不加括号来分组,就会出现错乱。因为用了FINDALL。

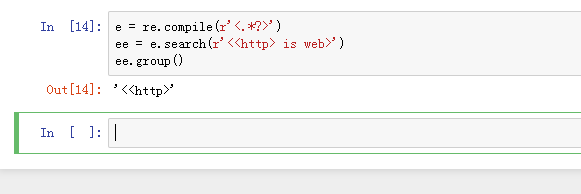
8、e = re.compile(r'<.*>')
ee = e.search(r'<<http> is web>')
ee.group()
e = re.compile(r'<.*?>')
ee = e.search(r'<<http> is web>')
ee.group()
在这种情况下加问号和不加问号有区别的,区别于选区的范围的大小。
9、f = re.compile(r'.*')
f.search('You are the man.\nWe are the man.').group()
f = re.compile(r'.*', re.DOTALL)
f.search('You are the man.\nWe are the man.').group()
因为换行的时候不会继续选取,所以用re.DOTALL就可以继续选取。

