1、跳表 实质是可进行二分查找的有序链表
原有链表上添加多级索引,通过索引实现快速查找
跳表不仅能提高搜索性能,同时提高插入、删除
每个元素插入时随机生成它的level
最低层包含所有的元素
如下图是跳表的最底层

2、如果一个元素出现在level(x),那么它肯定出现在x以下的level中
每个索引节点包含两个指针,一个向下,一个向右
时间复杂度 O(log n)
空间复杂度 O(n)
如下图,在最低层上建立一级索引。
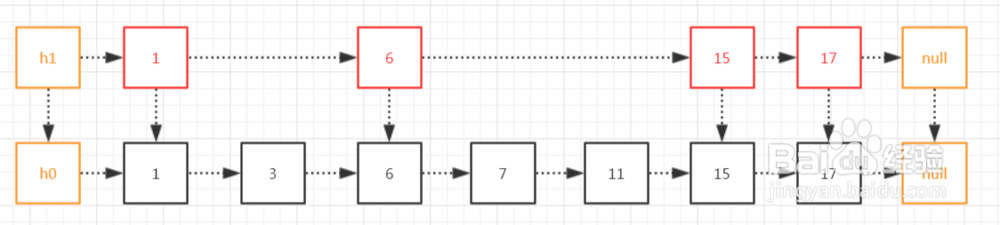
3、如下图,再在一级索引上,建立二级索引。这样,我们在访问一个数的时候,就先从最上层索引找,如果大于该数,就跳到下级索引,以此类推。

4、如下图,为跳表节点的添加。
首先,我们先根据投硬币的方式,决定8这个元素要占据的层数
比如,层数level=2。
然后,找到8这个元素在下面两层的前置节点。

5、如下图,为跳表的删除。

6、标准化的跳表如下图。

7、很像平衡二叉树,我们来看个元素个数多的情况。

8、为什么Redis选择使用跳表而不是红黑树来实现有序集合?
首先,我们来分析下Redis的有序集合支持的操作:
1)插入元素
2)删除元素
3)查找元素
4)有序输出所有元素
5)查找区间内所有元素
其中,前4项红黑树都可以完成,且时间复杂度与跳表一致。
但是,最后一项,红黑树的效率就没有跳表高了。
在跳表中,要查找区间的元素,我们只要定位到两个区间端点在最低层级的位置,然后按顺序遍历元素就可以了,非常高效。
而红黑树只能定位到端点后,再从首位置开始每次都要查找后继节点,相对来说是比较耗时的。
此外,跳表实现起来很容易且易读,红黑树实现起来相对困难,所以Redis选择使用跳表来实现有序集合。

9、下图为跳表在redis中的数据结构。分为zskiplist 和 zskiplistNode
以下为zskiplist结构。
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
} zskiplist;
zskiplistNode结构如下图所示。
