1、一段抓取互联网信息的程序
1、互联网数据,为我所用
可以爬去各种网络内容对自己的信息进行扩展或者扩充。
1、爬虫调度端
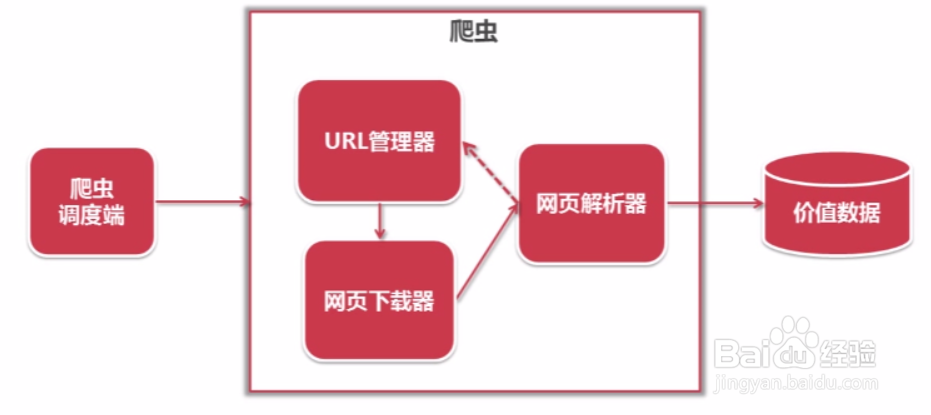
2、架构-运行流程
1. 调度器
2. URL管理器
3. 下载器
4. 解析器
5. 应用

1、URL:管理器
管理待抓取URL集合和已抓取URL集合
--防止重复抓取、防止循环抓取

2、实现方式:
内存:
1. python内存
2. MySQL
3. 缓存数据库

3、网页下载器
将互联网上URL对应的网页下载到本地的工具
(1)Python有哪几种下载器?
Urlib2 python官方基础模块
Requests 第三方包更强大

4、网页下载器 -urllib2
(1) 最简洁的读取
给定URL->urllib2.urlopen(url)

5、(2) 添加data、http header
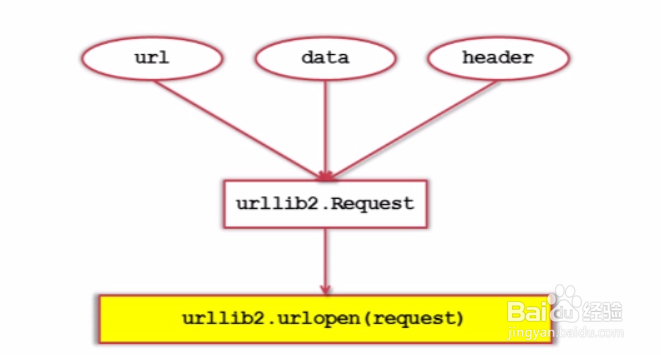

6、(3) 添加特殊情景的处理器


1


