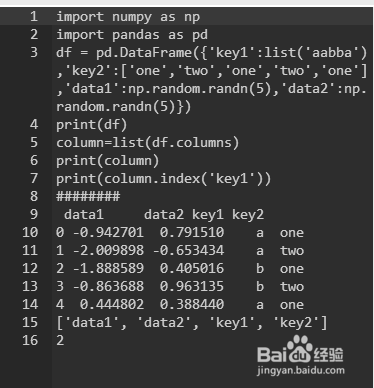
1、首先导入包
import numpy as np
import pandas as pd
2、###生成一个datdaframe ,用于测试
df = pd.DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
print(df)
3、column 为列名的列表
column=list(df.columns)
####index
print(column)
4、测试列明“key1”
###
print(column.index('key1'))
5、下面就是结果啦
"H:\Program Files\Anaconda3\python.exe" H:/Local/python/mycode/linshi
data1 data2 key1 key2
0 -0.942701 0.791510 a one
1 -2.009898 -0.653434 a two
2 -1.888589 0.405016 b one
3 -0.863688 0.963135 b two
4 0.444802 0.388440 a one
['data1', 'data2', 'key1', 'key2']
2
Process finished with exit code 0
6、2 即为位置 (从0开始) 顺利得到
7、index() 函数用于从列表中找出某个值第一个匹配项的索引位置。
感谢实验室小伙伴温、涛提供的方法