1、打开带抓取的网页,如下图:

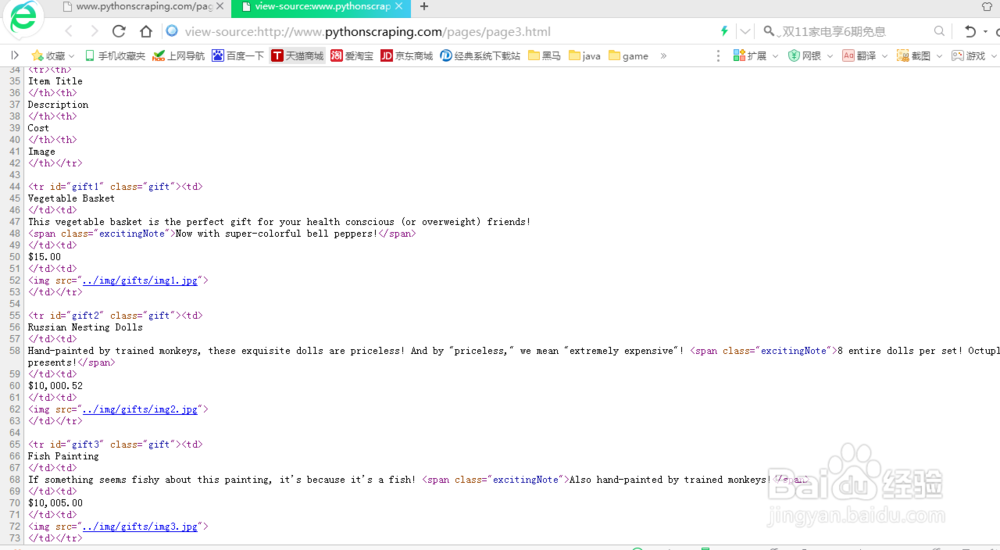
1、注意观察网页上有几个商品图片——它们的源代码形式如下:<img src="../img/gifts/img3.jpg">
如果我们想抓取所有图片的 URL 链接,非常直接的做法就是用 findAll("img") 抓取所图片,对吗?但是,有个问题。除了那些明显“多余的”图片(比如, LOGO) 之外,式的网站里都有一些隐藏图片, 用于网页布局留白和元素对齐的空白图片,以及一些不易察觉到的图片标签。总之,你不能仅用商品图片来统计网页上所有的图片。
2、而且网页的布局也可能会变化, 或者,因为某些原因,我们不想通过图片在网页中的位来查找标签。 那么当你想抓取随机分布在网站里的某个元素或数据时,就会出现问题。如,一些网页的最上面可能有一张商品图片,但是在另一些网页上没有。
3、解决这类问题的办法, 就是直接定位那些标签来查找信息。在本例中,我们直接通过商图片的文件路径来查找,如图中所示:
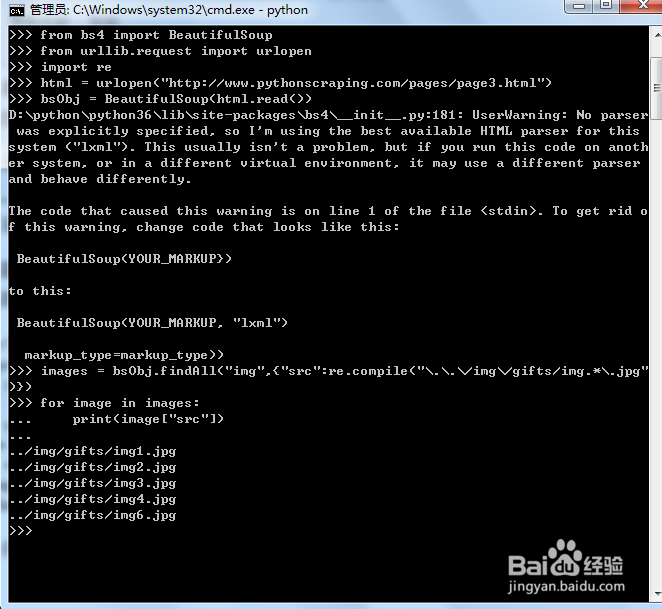
4、这段代码会打印出图片的相对路径,都是以 ../img/gifts/img 开头,以 .jpg 结尾,其结果下所示:../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
