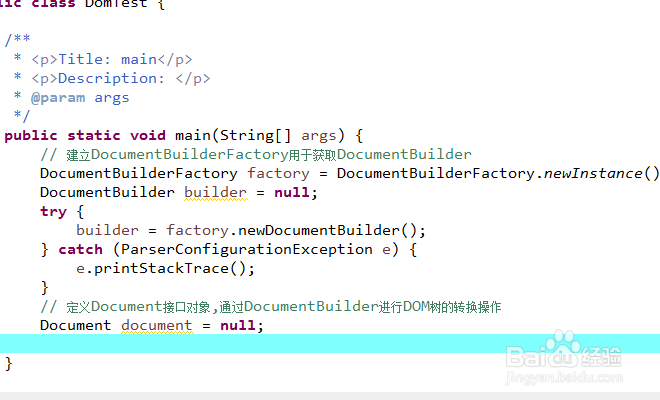
1、基于DOM(Document Object Model,文档对象模型)的XML解析器,将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。DOM树提供的随机访问方式给应用程序开发带来很大的灵活性,可以任意控制整个XML文档的内容。但文档较大或文档结构比较复杂时,对内存的要求就很高。下面我们进行DOM解析,首先建立DocumentBuilderFactory用于获取DocumentBuilder,再通过DocumentBuilder获取Document,如下图所示。
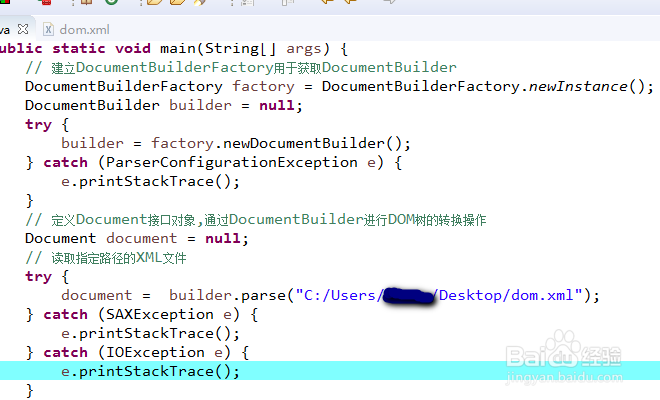
2、从指定的XML文件中读取出指定节点的内容,当使用builder.parse()操作时,实际上就相当于将所有的XML文档内容读取到内存中,从而将所有的XML文件内容按照节点定义的顺序将其变为内存中的一颗DOM树。
3、在DOM解析中,每一个节点中的内容实际上都是一个单独的文本节点,获取到节点的NodeList后,取得第一个子节点的第一个文本节点,并使用getNodeValue()获取节点的内容。
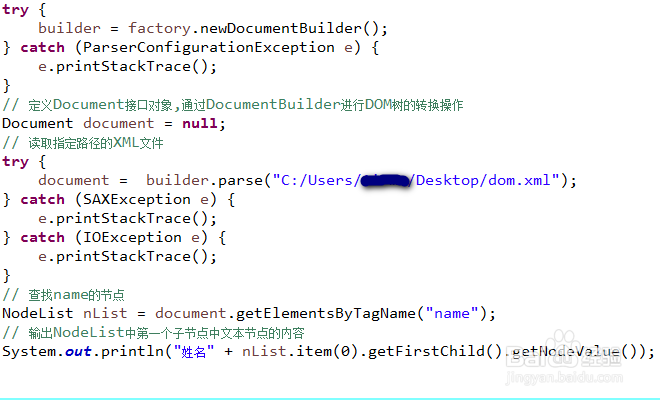
4、代码编写完成后运行程序,我们查看一下原XML文件和程序输出的结果,可以看到xml文件被正常解析,并取到了我们想要的值。
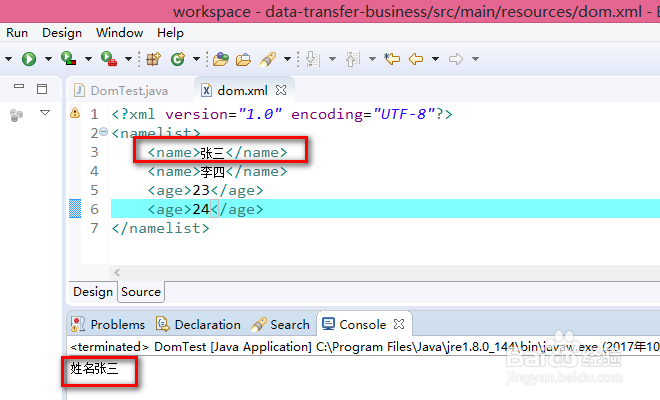
5、以上简单的xml文件解析便完成了,值得注意的是,我们在编程中所导入的包一定要是import org.w3c.dom.*,否则在编程中会出现找不到方法等问题。
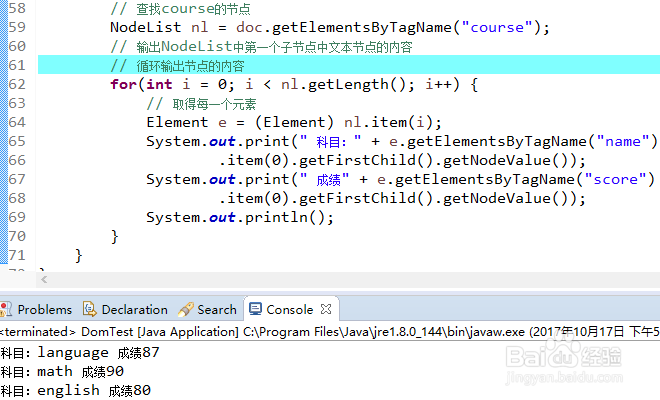
6、此外,我们再介绍一种循环遍历出所有节点的方法,如下图使用for循环遍历出一个学生成绩的xml文件,并打印出科目和成绩信息。